The ability to classify music in an automated manner has become increasingly more important with the advent of musical streaming services allowing greater access to music. Spotify alone hit 100 million users in 2016, with other services provided by companies such as Apple, Soundcloud and YouTube. In addition, there are huge numbers of professional musicians, approximately 53,000 in the USA alone, as well as amateurs who are producing music which needs to be classified. With this quantity of music, it is unfeasible to classify genres without an automated method.
Introduction
The aim of this project is to try to develop a classifier for song genres using only its lyrics. Firstly, a dataset of song lyrics and their associated genres needs to be produced. Therefore, I build a crawler to get the dataset, which I will not demonstate in this article. Secondly, a review of the potential classification models needs to be undertaken to determine which is most likely to be successful in this task. I will compare conventional machine learning models to state-of-the-art deep learning models. Thirdly, a final result should be produced with the optimised model. This will then be reviewed with comparison to both ML and DL models to determine what areas are working successfully and where there are remaining issues, which still need to be overcome.
Exploratory Data Analysis
Import Libraries
import re
import warnings
import pandas as pd
import numpy as np
from tqdm import tqdm
warnings.filterwarnings("ignore")
import sys
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
from sklearn.model_selection import train_test_split
from collections import defaultdict
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from gensim.models import KeyedVectors
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.model_selection import cross_val_scoreLoad the data.
data = pd.read_csv("./lyrics.csv", delimiter=",")
data.head()
Data Processing
There are lots of techniques for NLP data processing, such as noise removal (remove stopwords), lexicon normalisation (stemming, lemmatisation), object standardisation (acronyms, hash tags, colloquial slangs), etc. However, these are out of the scope in this article, instead, I will only do tokenisation. I wrote an [article] that teachs you how to do a proper EDA on your data.
def tokenization(text):
text = re.split('\W+', text)
return text
data["lyrics_tokenised"] = data["lyrics"].apply(lambda x: tokenization(str(x).lower()))Segregated data into training (40%), validation (20%), and testing (20%) dataset.
lyrics = data['lyrics_tokenised'].values
genres = data['genre'].apply(str).values
X_train, X_test, y_train, y_test = train_test_split(
lyrics, genres, test_size=0.4, random_state=914, stratify=genres)
X_valid, X_test, y_valid, y_test = train_test_split(
X_test, y_test, test_size=0.5, random_state=914, stratify=y_test)There are 217342, 72447, 72447 samples of training, validation, and testing dataset, respectively.
Word Embedding
I utilised three word embedding vectorisers MeanEmbeddingVectorizer(), TfidfEmbeddingVectorizer(), and SifEmbeddingVectorizer() from one of my [post].
# Word2Vec
vectoriser_w2v_mean = MeanEmbeddingVectorizer(word2vec=w2v_model)
feature_train_w2v_mean = vectoriser_w2v_mean.fit_transform(X_train, None)
vectoriser_w2v_tfidf = TfidfEmbeddingVectorizer(word2vec=w2v_model)
feature_train_w2v_tfidf = vectoriser_w2v_tfidf.fit_transform(X_train, None)
vectoriser_w2v_sif = SifEmbeddingVectorizer(word2vec=w2v_model)
feature_train_w2v_sif = vectoriser_w2v_sif.fit_transform(X_train, None)
# GloVe
vectoriser_glove_mean = MeanEmbeddingVectorizer(word2vec=glove_model)
feature_train_glove_mean = vectoriser_glove_mean.fit_transform(X_train, None)
vectoriser_glove_tfidf = TfidfEmbeddingVectorizer(word2vec=glove_model)
feature_train_glove_tfidf = vectoriser_glove_tfidf.fit_transform(X_train, None)
vectoriser_glove_sif = SifEmbeddingVectorizer(word2vec=glove_model)
feature_train_glove_sif = vectoriser_glove_sif.fit_transform(X_train, None)
# FastText
vectoriser_ft_mean = MeanEmbeddingVectorizer(word2vec=ft_model)
feature_train_ft_mean = vectoriser_ft_mean.fit_transform(X_train, None)
vectoriser_ft_tfidf = TfidfEmbeddingVectorizer(word2vec=ft_model)
feature_train_ft_tfidf = vectoriser_ft_tfidf.fit_transform(X_train, None)
vectoriser_ft_sif = SifEmbeddingVectorizer(word2vec=ft_model)
feature_train_ft_sif = vectoriser_ft_sif.fit_transform(X_train, None)After a long period of time, finally got the embedding vectors! Let’s put them into dictionaries vectorisers_dcit and features_train_dict for later use.
Modelling
Introduction
This is a supervised text classification problem, and our goal is to investigate which supervised machine learning methods are best suited to solve it. Given a new lyrics comes in, we want to assign it to one of the twelve categories. This is a multi-class text classification task.
Imbalanced Classes
Let’s take a look at the distribution of label in training dataset.
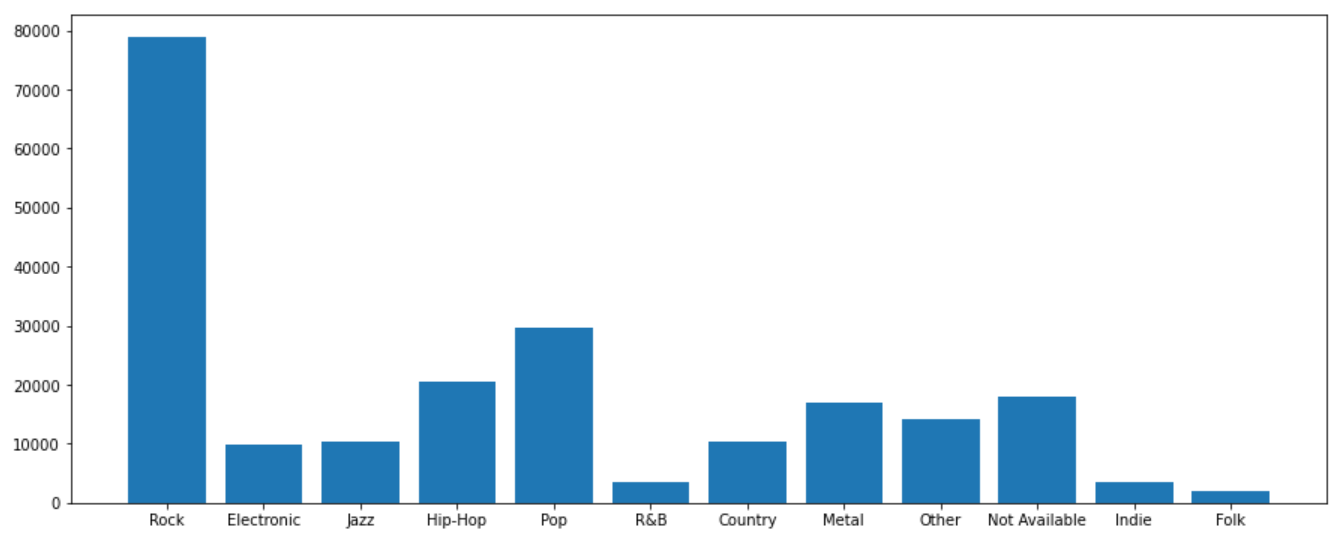
We can see that the number of genres per song is imbalanced. Genres of the songs are more biased towards “Rock” music. When we encounter such problems, we are bound to have difficulties solving them with standard algorithms, Conventional algorithms are often biased towards the majority classes, not taking the data distribution into account. In the worst case, minority classes are considered as outliers or being ignored. For some cases, such as fraud detection or cancer prediction, we would need to carefully configure our model or artificially balance the dataset, for instance, using resampling technique (under-sampling, over-sampling), Tomek Links, SMOTE (Synthetic Minority Oversampling Technique), class weights in the models, or changing your evaluation metrics.
Various other methods might work depending on your use case and the problem you are trying to solve.
- Collect more data
- Treat the problem as anomaly detection (e.g. isolation forests, autoencoders, …)
- Model-based approach (boosting models, …)
However, in our case, I will not operate any of the techniques mentioned above, I will leave it as it is.
Baseline
We are now ready to experiment with different machine learning models, evaluate their accuracy and find the source of any potential issues.
We will benchmark the following three models:
- Random Forest
- Linear Support Vector Machine
- Logistic Regression
I also built same models for 9 different weighted embedding method: word2vec-mean, word2vec-tfidf, word2vec-sif, glove-mean, glove-tfidf, glove-sif, fasttext-mean, fasttext-tfidf, and fasttext-sif.
After calculating for all the cv dataframe, you will get something like the following:

Give this some plots: (if you want to visulise them by yourself to capture some interesting point, I’ll put the csv file over here)
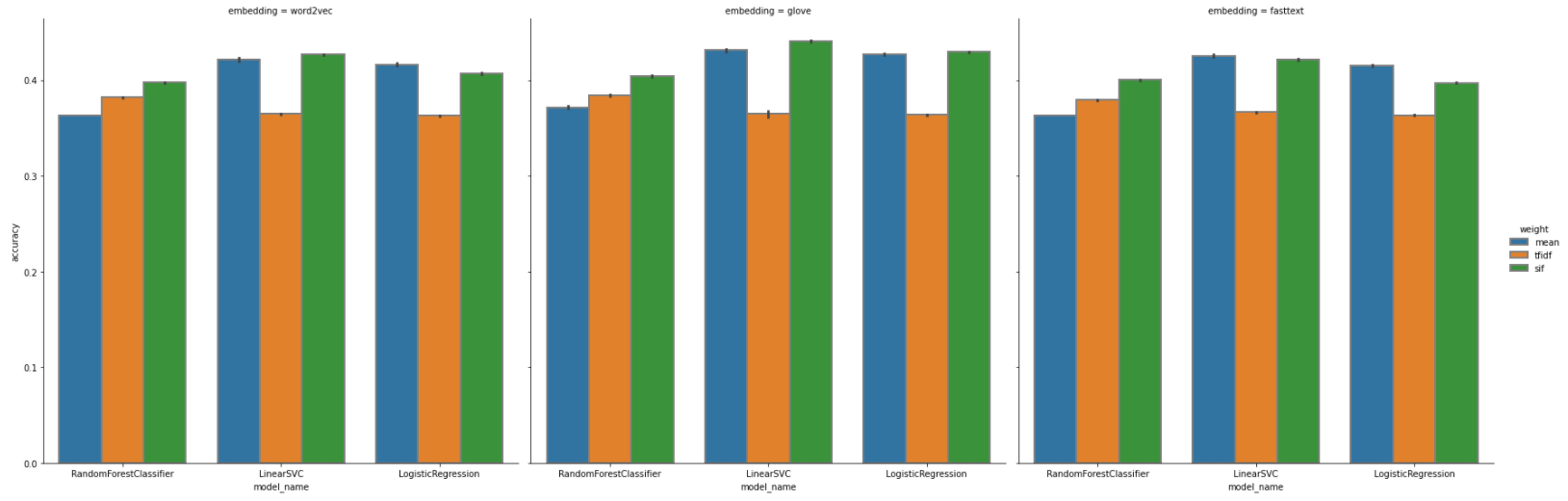
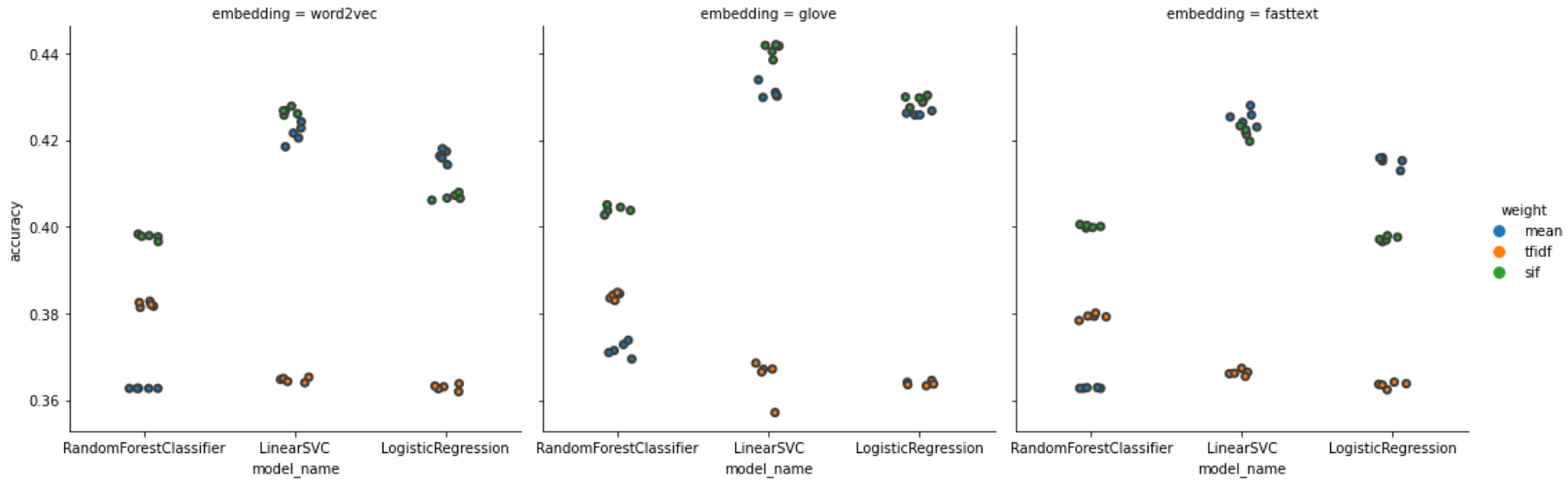
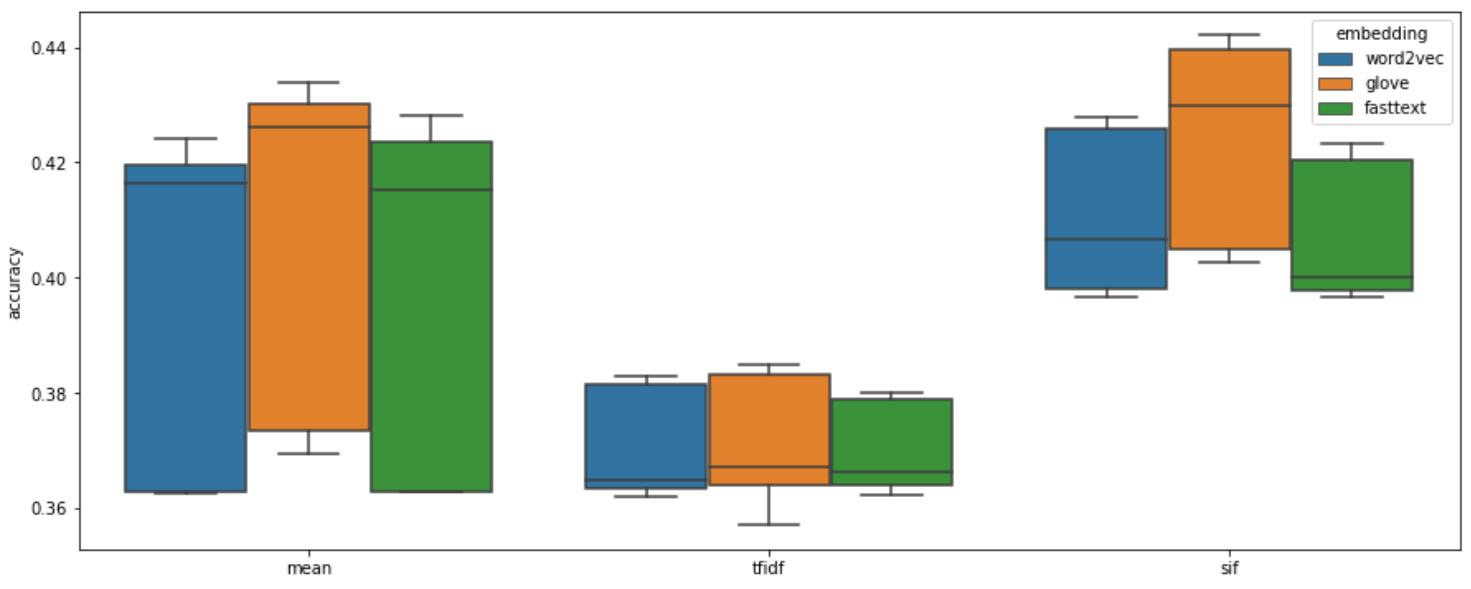
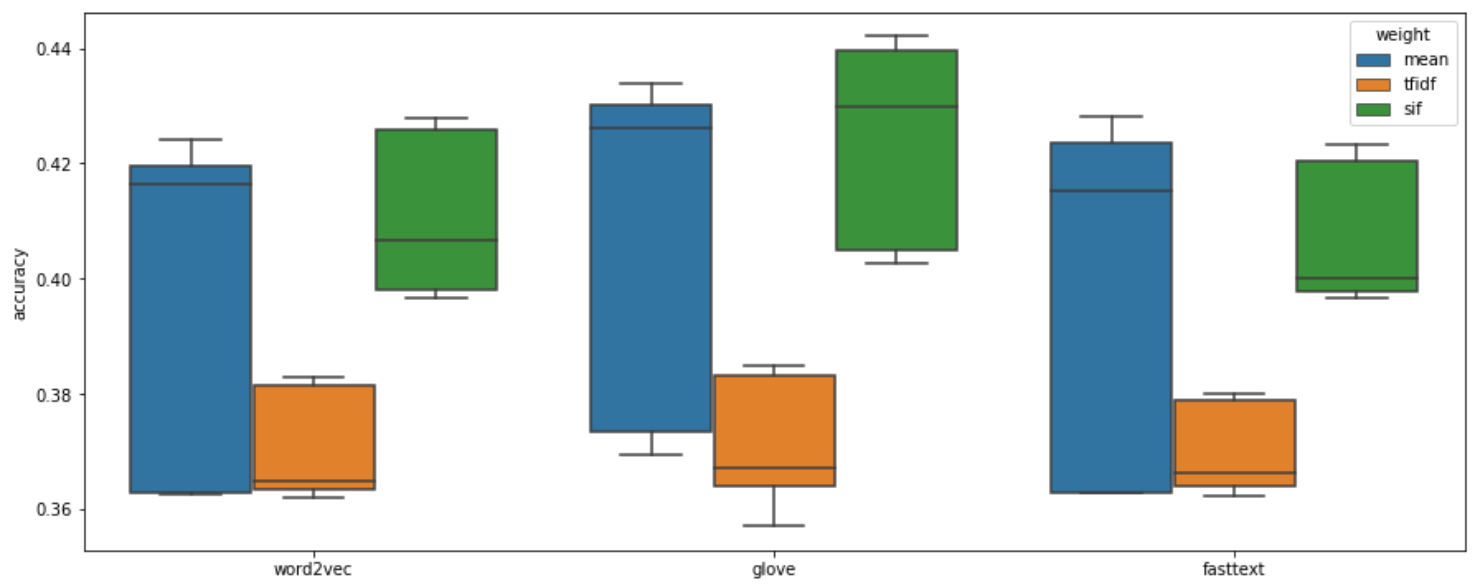
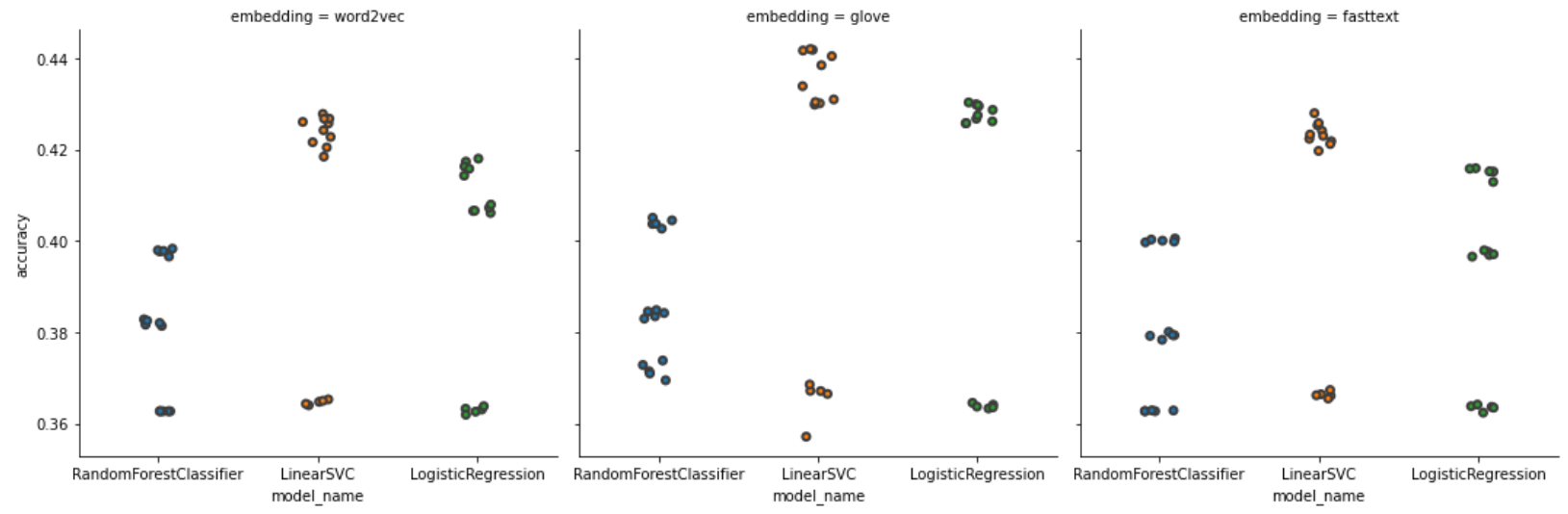
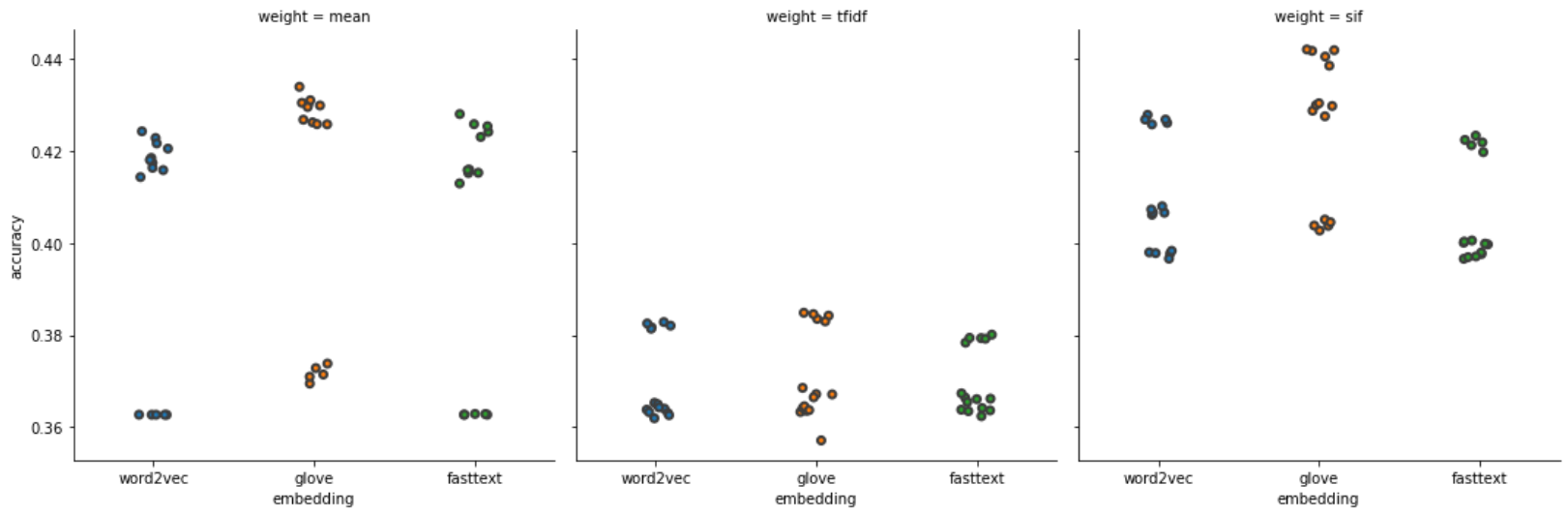
The figures tell us some intriguing points:
- LinearSVC (mean acc: 0.4070) and LogisticRegression (mean acc: 0.3979) perform slightly better than RandomForest (mean acc: 0.3826).
- SIF usually has better accuracy and has lower variance comparing to TF-IDF and averaging method.
- Integrating GloVe embedding model with SIF weight seems to be the best choice to this task. Top 1, top 2, and top 3 model are all embedding with GloVe model, having a mean accuracy around 42%.
| Model Name | Weight | Embedding | Accuracy |
|---|---|---|---|
| LinearSVC | mean | fasttext | 0.425256 |
| glove | 🥈 0.431067 | ||
| word2vec | 0.421520 | ||
| sif | fasttext | 0.421695 | |
| glove | 🥇 0.440918 | ||
| word2vec | 0.426650 | ||
| tfidf | fasttext | 0.366289 | |
| glove | 0.365272 | ||
| word2vec | 0.364651 | ||
| LogisticRegression | mean | fasttext | 0.415023 |
| glove | 0.426816 | ||
| word2vec | 0.416371 | ||
| sif | fasttext | 0.397213 | |
| glove | 🥉 0.429250 | ||
| word2vec | 0.406907 | ||
| tfidf | fasttext | 0.363473 | |
| glove | 0.363828 | ||
| word2vec | 0.362917 | ||
| RandomForestClassifier | mean | fasttext | 0.362760 |
| glove | 0.371686 | ||
| word2vec | 0.362682 | ||
| sif | fasttext | 0.400079 | |
| glove | 0.403953 | ||
| word2vec | 0.397659 | ||
| tfidf | fasttext | 0.379264 | |
| glove | 0.384008 | ||
| word2vec | 0.382075 |
Deep Learning Model
In this project, I used tez, a simple PyTorch wrapper, to design our deep learning model structure. This library keeps things super simple and customisable.
Import Libraries
import tez
import torch.nn as nn
import pandas as pd
import numpy as np
import torchimport transformers
from collections import Counter
from sklearn import metrics, model_selection, preprocessing
from transformers import AdamW, get_linear_schedule_with_warmupBuild Dataset
PyTorch provides many tools to make data loading easy and hopefully, to make your code more readable. In this section, we will see how to load and preprocess data from a custom dataset. In this Dataset class, I tokenize the lyrics, and break them up into word and subwords in the format DistilBERT is comfortable with.
Before we can hand our lyrics to SongGenreDistilbertClassifier(), we need to do some minimal processing to put them in the format it requires.
- Tokenise: break them up into word and subwords.
- Padding: pad all lists to the same size.
- Masking: ignore (mask) the padding we’ve added when it’s processing its input.
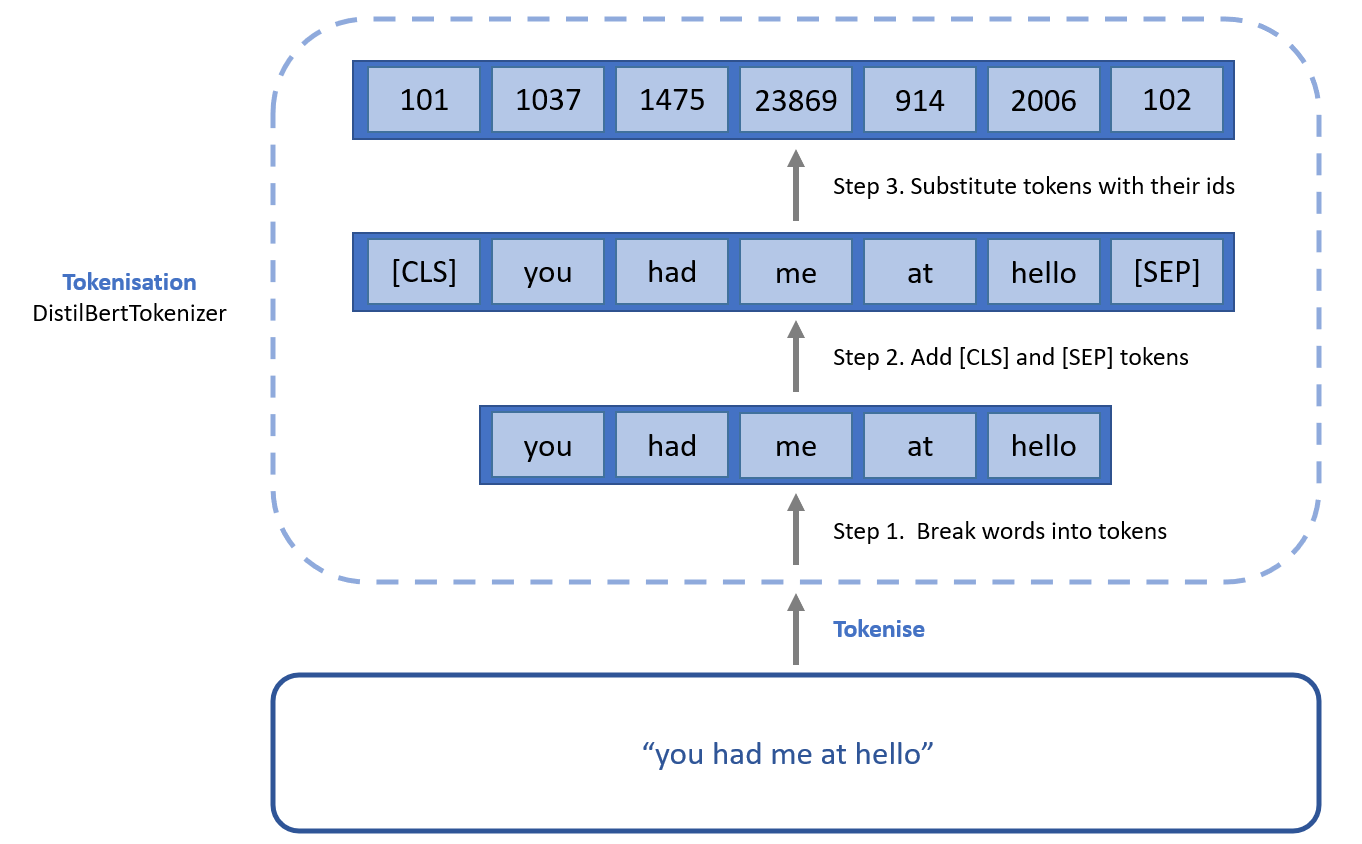
class DistilbertDataset:
def __init__(self, text, target):
self.text = text
self.target = target
self.tokenizer = transformers.DistilBertTokenizer.from_pretrained(
"distilbert-base-uncased", do_lower_case=True, use_fast=False
)
self.max_len = 64
def __len__(self):
return len(self.text)
def __getitem__(self, item):
text = str(self.text[item])
text = " ".join(text.split())
inputs = self.tokenizer.encode_plus(
text,
None,
add_special_tokens=True,
max_length=self.max_len,
padding="max_length",
truncation=True,
)
ids = inputs["input_ids"]
mask = inputs["attention_mask"]
return {
"ids": torch.tensor(ids, dtype=torch.long),
"mask": torch.tensor(mask, dtype=torch.long),
"targets": torch.tensor(self.target[item], dtype=torch.long),
}Build Model
A typical training procedure for a neural network is as follows:
- Define the neural network that has some learnable parameters (or weights)
- Iterate over a dataset of inputs
- Process input through the network
- Compute the loss (how far is the output from being correct)
- Propagate gradients back into the network’s parameters
- Update the weights of the network, typically using a simple update rule:
weight = weight - learning_rate * gradient
BERT
BERT is a new language representation model, which stands for Bidirectional Encoder from Transformer, published by researchers at Google AL Language. In this work, I will talk about DistilBERT, which is a smaller, faster, cheaper and lighter version of BERT. DistilBERT uses a technique called distillation, which approximates the BERT, the larger neural network by a smaller one. The idea is that once a large neural network has been trained, its full output distributions can be approximated using a smaller network. However, the basic structure of DistilBERT almost remain the same as BERT, and it retains 95% performance but using only half the number of parameters.
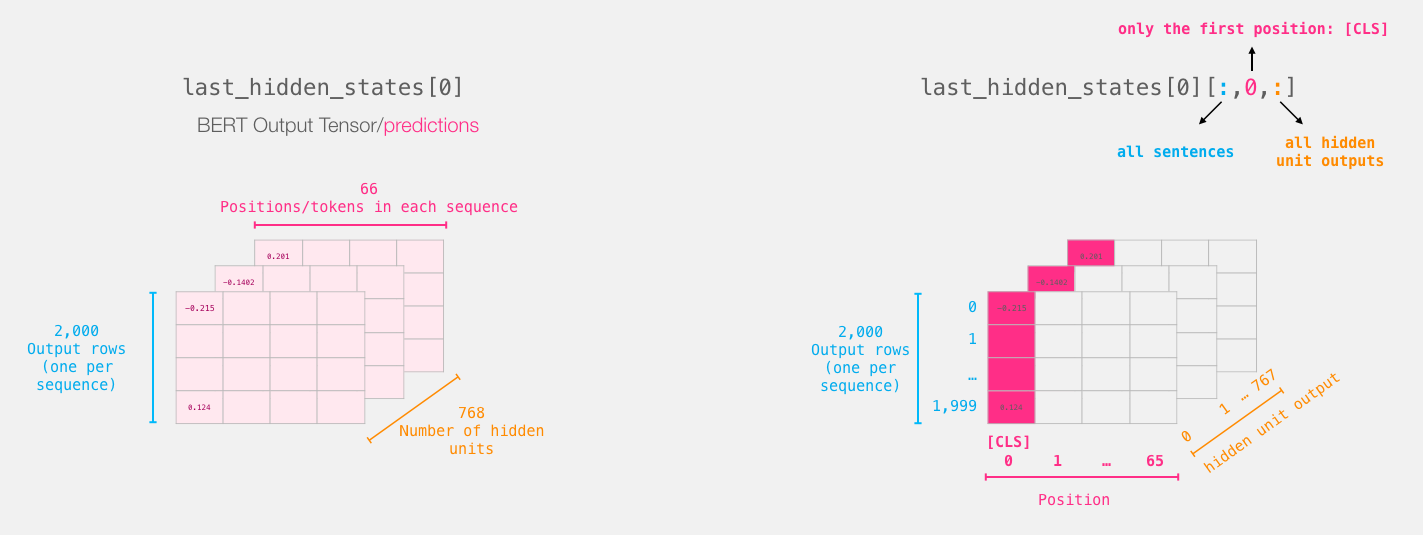
The forward() function runs our lyrics through DistilBERT. The results of the processing will be returned into last_hidden_states. Let’s slice only the part of the output that we need. That is the output corresponding the first token of each sentence. The way BERT does sentence classification, is that it adds a token called [CLS] at the beginning of every sentence. The output corresponding to that token can be thought of as an embedding for the entire sentence. The shape of last_hidden_states[0] sequentially contains lyrics, position of every tokens, hidden unit outputs. We’ll then save those in the features variable, as they’ll serve as the features to our fully connection layer.
Let’s define the network SongGenreDistilbertClassifier() using pertrained model from HuggingFace:
class SongGenreDistilbertClassifier(tez.Model):
def __init__(self, num_train_steps, num_classes):
super().__init__()
self.tokenizer = transformers.DistilBertTokenizer.from_pretrained(
"distilbert-base-uncased", do_lower_case=True
)
self.bert = transformers.DistilBertModel.from_pretrained(
"distilbert-base-uncased",
return_dict=False)
self.bert_drop = nn.Dropout(0.3)
self.out = nn.Linear(self.bert.config.dim, num_classes)
self.num_train_steps = num_train_steps
self.step_scheduler_after = "batch"
def fetch_optimizer(self):
param_optimizer = list(self.named_parameters())
no_decay = ["bias", "LayerNorm.bias"]
optimizer_parameters = [
{
"params": [
p for n, p in param_optimizer if not any(nd in n for nd in no_decay)
],
"weight_decay": 0.001,
},
{
"params": [
p for n, p in param_optimizer if any(nd in n for nd in no_decay)
],
"weight_decay": 0.0,
},
]
opt = AdamW(optimizer_parameters, lr=3e-5)
return opt
def fetch_scheduler(self):
sch = get_linear_schedule_with_warmup(
self.optimizer, num_warmup_steps=0, num_training_steps=self.num_train_steps
)
return sch
def loss(self, outputs, targets):
if targets is None:
return None
return nn.CrossEntropyLoss()(outputs, targets)
def monitor_metrics(self, outputs, targets):
if targets is None:
return {}
outputs = torch.argmax(outputs, dim=1).cpu().detach().numpy()
targets = targets.cpu().detach().numpy()
accuracy = metrics.accuracy_score(targets, outputs)
f1_score = metrics.f1_score(targets, outputs, average='weighted')
return {"accuracy": accuracy, "f1": f1_score}
def forward(self, ids, mask, targets=None):
last_hidden_states = self.bert(ids, attention_mask=mask)
b_o = self.bert_drop(last_hidden_states[0][:, 0, :])
output = self.out(b_o)
loss = self.loss(output, targets)
acc = self.monitor_metrics(output, targets)
return output, loss, acc
def score(self, valid_dataset, batch_size=64, n_jobs=-1):
preds = self.predict(valid_dataset, batch_size=64, n_jobs=-1)
preds = np.array(list(flatten(list(preds))))
preds = preds.reshape(len(valid_dataset), 12)
preds = np.argmax(preds, axis=1)
targets = valid_dataset[:]["targets"].numpy()
acc = metrics.accuracy_score(targets, preds)
f1 = metrics.f1_score(targets, preds, average='weighted')
return acc, f1Preparing the Dataset
data = pd.read_csv("./lyrics.csv", delimiter=",")
data = data.dropna(subset=["lyrics"]).reset_index(drop=True)
lbl_enc = preprocessing.LabelEncoder()
data.genre = lbl_enc.fit_transform(data.genre.values)
df_train, df_valid = model_selection.train_test_split(
data, test_size=0.1, random_state=42, stratify=data.genre.values
)
df_train = df_train.reset_index(drop=True)
df_valid = df_valid.reset_index(drop=True)
train_dataset = DistilbertDataset(
text=df_train.lyrics.values, target=df_train.genre.values
)
valid_dataset = DistilbertDataset(
text=df_valid.lyrics.values, target=df_valid.genre.values
)Start Training
n_train_steps = int(len(df_train) / 32 * 10)
model = SongGenreDistilbertClassifier(
num_train_steps=n_train_steps, num_classes=len(Counter(data.genre).keys())
)
tb_logger = tez.callbacks.TensorBoardLogger(log_dir="./logs/")
es = tez.callbacks.EarlyStopping(monitor="valid_loss",
model_path="./output/diltilbert.bin",
patience=10,
mode="max",)
model.fit(
train_dataset,
valid_dataset=valid_dataset,
train_bs=8,
device="cuda",
epochs=5,
callbacks=[tb_logger, es],
fp16=True,
)
model.save("./output/diltilbert.bin")Evaluate the Model
model.load("output/diltilbert.bin", device="cuda")
acc, f1 = model.score(valid_dataset, batch_size=64, n_jobs=-1)Performance
Without doing text preprocessing step or standard tokenisation technique, pre-trained models leads to a big performance increase, making it competitive with other conventional machine learning models.
| Model Name | Accuracy | F1-score |
|---|---|---|
| BERT | 0.55998 | 🥇 0.53611 |
| DistilBERT | 0.56167 | 🥈 0.53433 |
| ALBERT | 0.50131 | 0.42038 |
| ELECTRA | 0.54820 | 0.50825 |
| XLNet | 0.55214 | 🥉 0.52457 |
Conclusion
In this article, you’ve learned how you can train BERT, DistilBERT, ALBERT, ELECTRA, and XLNet using Huggingface Transformers library on your dataset. Note that, you can also use other transformer models, such as GPT-2 with GPT2ForSequenceClassification, RoBERTa with GPT2ForSequenceClassification, and much more.

