Introduction
This article aims to build a web scraper by using BeautifulSoup and Selenium, and scrape QS Rankings to discover the top universities from all over the world. “Uni name”, “ranking” and “location” are fetched from the table and stored as a csv file. Jupyter notebook is available as well through this link.
Python Implementation
Download chrome web dirver first.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import time
import bs4
from bs4 import BeautifulSoup
from selenium.common.exceptions import *
from selenium import webdriver
%matplotlib inlineMain Code
Only 25 universities are listed on the table per page, so I have to set the number of page I want to crawl. (max page: 40)
- Open the html via chrome driver. (make sure webdriver.exe is in the same directory)
- Parse the html using BeautifulSoup.
- Create a loop to crawl all the elements (ranking, uni name, location) in each row.
- Click to the next page and start over the loop in step three.
- Stop fetching the data until all pages are done.
def get_uni_information(year=2020, unilist, page=40):
url = r"https://www.topuniversities.com/university-rankings/world-university-rankings/{}".format(year)
# Open url and get the QS Ranking html page
driver_path = r"C:\Users\YangWang\Desktop\machineLearning\indiaNewsClassification\chromedriver.exe"
driver = webdriver.Chrome(driver_path)
time.sleep(2)
driver.get(url)
time.sleep(5)
# Crawl all the pages (max page is 40)
if page <= 40:
for _ in range(int(page)):
# Use BeautifulSoup to parse every page
soup = BeautifulSoup(driver.page_source, "html.parser")
# Find the table which contains the information I want
x = soup.find(name="table", attrs={"class": "dataTable no-footer"})
# Use 'for' loop to catch every rows in the table, and append the rows into the list
for tr in x.find(name="tbody"):
try:
tds = tr('td')
if tds[0].find(name="span") is not None:
rank = tds[0].find(name="span").string
else:
rank = None
if tds[1].find(name="a") is not None:
uni = tds[1].find(name="a").string
else:
uni = None
if tds[2].find(attrs={"class": "td-wrap"}) is not None:
location = tds[2].find(attrs={"class": "td-wrap"}).string
else:
location = None
except (RuntimeError, TypeError, NameError):
pass
unilist.append([rank, uni, location])
# Click next page button
element = driver.find_element_by_xpath('//*[@id="qs-rankings_next"]')
driver.execute_script("arguments[0].click();", element)
time.sleep(5)
else:
print("Max page is 40.")
driver.quit()
return unilistGet the DataFrame
Using get_uni_information() function to crawl the information and then store them into a dataframe. Also do some dataframe preprocessing in order to make sure every columns are in right data types.
def get_qs_ranking_dataframe(year=2020, page=40):
unilist = []
unilist = get_uni_information(year, unilist, page)
df = pd.DataFrame(unilist)
df.columns = ["ranking", "uni", "location"]
df.reset_index(drop=True)
# Dataframe preprocessing
df["ranking"] = [int(x)+1 for x in range(len(df))]
df["uni"] = df["uni"].map(str)
df["location"] = df["location"].map(str)
return dfTake a look at the dataframe.
Japan
qs_2020 = get_qs_ranking_dataframe(year=2020, page=40)
qs_2020[(qs_2020["location"] == "Japan") & (qs_2020["ranking"] <= 100)]| ranking | uni | location |
|---|---|---|
| 23 | The University of Tokyo | Japan |
| 34 | Kyoto University | Japan |
| 59 | Tokyo Institute of Technology (Tokyo Tech) | Japan |
| 71 | Osaka University | Japan |
| 82 | Tohoku University | Japan |
United States
qs_2020[(qs_2020["location"] == "United States") & (qs_2020["ranking"] <= 100)]| ranking | uni | location |
|---|---|---|
| 1 | Massachusetts Institute of Technology (MIT) | United States |
| 2 | Stanford University | United States |
| 3 | Harvard University | United States |
| 5 | California Institute of Technology (Caltech) | United States |
| 10 | University of Chicago | United States |
| 13 | Princeton University | United States |
| 14 | Cornell University | United States |
| 15 | University of Pennsylvania | United States |
| 17 | Yale University | United States |
| 18 | Columbia University | United States |
| 21 | University of Michigan-Ann Arbor | United States |
| 24 | Johns Hopkins University | United States |
| 25 | Duke University | United States |
| 28 | University of California, Berkeley (UCB) | United States |
| 31 | Northwestern University | United States |
| 36 | University of California, Los Angeles (UCLA) | United States |
| 39 | New York University (NYU) | United States |
| 45 | University of California, San Diego (UCSD) | United States |
| 48 | Carnegie Mellon University | United States |
| 56 | University of Wisconsin-Madison | United States |
| 57 | Brown University | United States |
| 65 | University of Texas at Austin | United States |
| 68 | University of Washington | United States |
| 72 | Georgia Institute of Technology | United States |
| 74 | University of Illinois at Urbana-Champaign | United States |
| 86 | Rice University | United States |
| 90 | University of North Carolina, Chapel Hill | United States |
| 93 | Pennsylvania State University | United States |
| 98 | Boston University | United States |
United Kingdom
qs_2020[(qs_2020["location"] == "United Kingdom") & (qs_2020["ranking"] <= 100)]| ranking | uni | location |
|---|---|---|
| 4 | University of Oxford | United Kingdom |
| 7 | University of Cambridge | United Kingdom |
| 8 | UCL | United Kingdom |
| 9 | Imperial College London | United Kingdom |
| 20 | The University of Edinburgh | United Kingdom |
| 27 | The University of Manchester | United Kingdom |
| 33 | King’s College London | United Kingdom |
| 44 | The London School of Economics and Political S… | United Kingdom |
| 49 | University of Bristol | United Kingdom |
| 62 | The University of Warwick | United Kingdom |
| 67 | University of Glasgow | United Kingdom |
| 77 | Durham University | United Kingdom |
| 78 | The University of Sheffield | United Kingdom |
| 81 | University of Birmingham | United Kingdom |
| 94 | University of Leeds | United Kingdom |
| 96 | University of Nottingham | United Kingdom |
| 97 | University of Southampton | United Kingdom |
| 100 | University of St Andrews | United Kingdom |
Taiwan
qs_2020[(qs_2020["location"] == "Taiwan") & (qs_2020["ranking"] <= 1000)]| ranking | uni | location |
|---|---|---|
| 69 | National Taiwan University (NTU) | Taiwan |
| 174 | National Tsing Hua University | Taiwan |
| 226 | National Cheng Kung University (NCKU) | Taiwan |
| 228 | National Chiao Tung University | Taiwan |
| 251 | National Taiwan University of Science and Tech… | Taiwan |
| 288 | National Yang Ming University | Taiwan |
| 333 | National Taiwan Normal University | Taiwan |
| 381 | Taipei Medical University (TMU) | Taiwan |
| 412 | National Sun Yat-sen University | Taiwan |
| 427 | National Central University | Taiwan |
| 485 | Chang Gung University | Taiwan |
| 514 | National Taipei University of Technology | Taiwan |
| 556 | National Chengchi University | Taiwan |
| 669 | Kaohsiung Medical University | Taiwan |
| 675 | National Chung Hsing University | Taiwan |
| 866 | National Chung Cheng University | Taiwan |
Visualise
Visualise top top_ranking universities and show top num countries in the image of the certain year.
def visualise_qs_ranking(df, year, top_ranking, num):
"""
df: dataframe
year: year of the qs ranking
top_ranking: top # of universities to be selected
num: # of countries to be visaulised
"""
plt.style.use('seaborn-paper')
top = df.iloc[0:top_ranking]
ax = (top['location'].value_counts().head(num).plot(
kind='barh',
figsize=(20, 10),
color="tab:blue",
title="Number of Top {} Universities in QS Ranking {}".format(len(top['location']), str(year))))
ax.set_xticks(np.arange(0, top['location'].value_counts()[0]+2, 1))
visualise_qs_ranking(df=qs_2020, year=2020, top_ranking=100, num=10)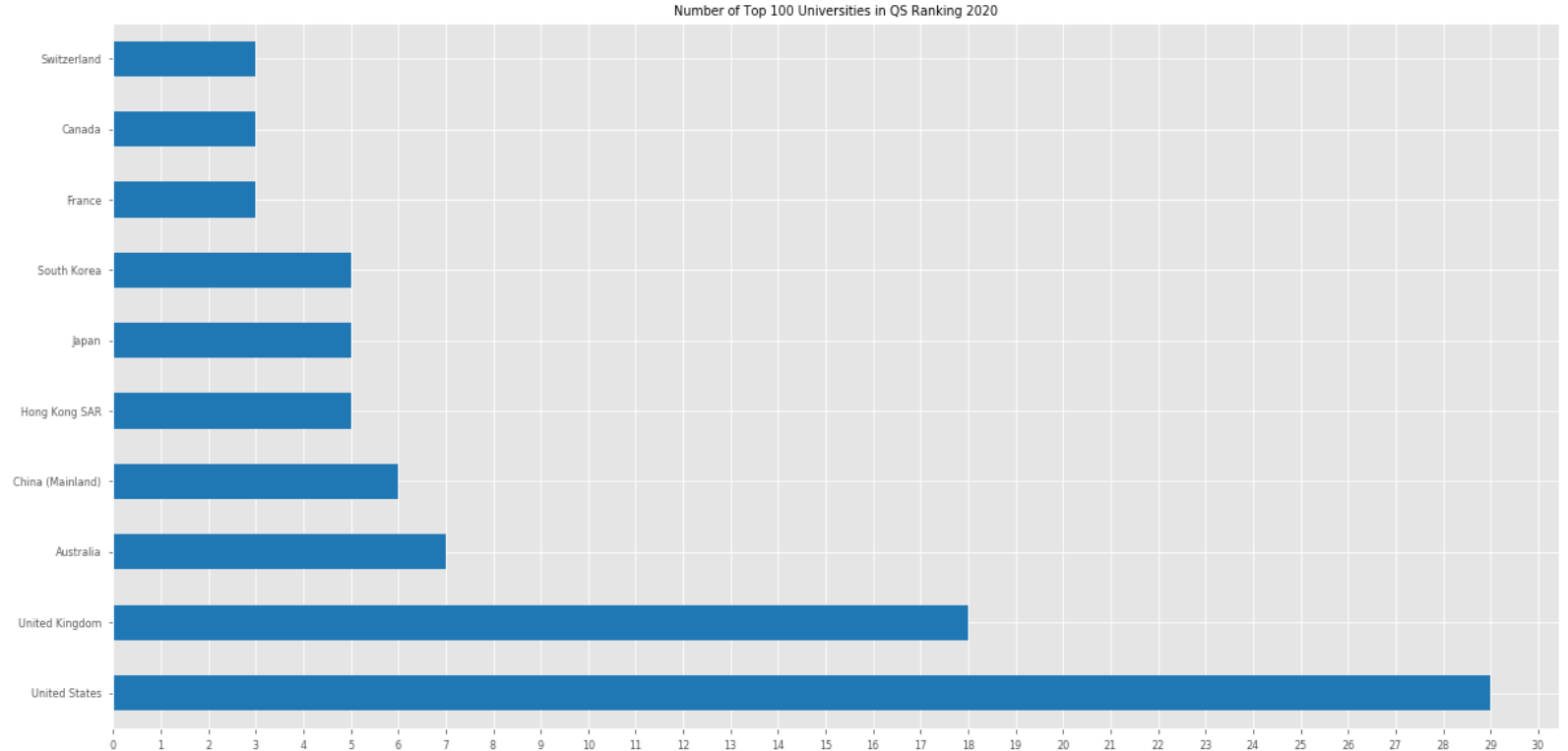
Conclusion
The above is a combination of Python’s Selenium and BeautifulSoup to achieve dynamic web crawler, the complete code can be found in my GitHub, if you encounter problems in the process of implementation, welcome to share in the comments below.

