A web crawler, sometimes called a spiderbot or scraper, is an internet bot that systematically browses the net. We can get the information we need without copy-paste. The goal of this article is to let you know how I scrape web and store it into database or csv file.
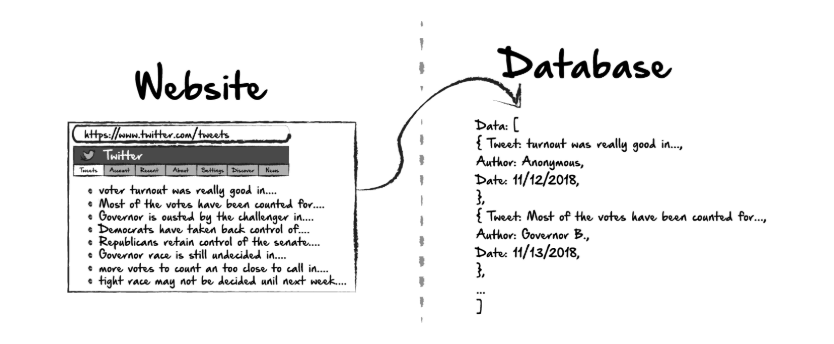
Build a Web Crawler as a Beginner
Wrting scripts with computer languanges are predominantly used by programmers. However, beginners may not know how to set up environment for their first program, and also not able to debug in a text editor or IDE. I suggest you to read through this article) first before kickstarting this tutorial.
Assume that you have already built your virtual environment using conda, open your notebook using jupyter notebook in command line.
Crawler Workflow
In general, web scraping using Python invloves three main steps:
- Send a request to the URL to the website.
- Since the website are usually written in HTML, we need to parse the website to a tree structure.
- Store our result in a dictionary or list for future use.
Next, I will demonstrate the three steps above to scrape volleyball game stats from WorldofVolley website. Let’s get started!
Time to Crawl
For stats table in the website, you will see every rows represents different match on different dates. You can’t help but ask: So how do you see the data that the browser secretly downloads? The answer is the F12 shortcut in Google Chrome, or you can open the developer tools that come with Chrome through the right-click menu inspect.The developer tools will appear on the left side of the browser page or below (adjustable), it looks like this:
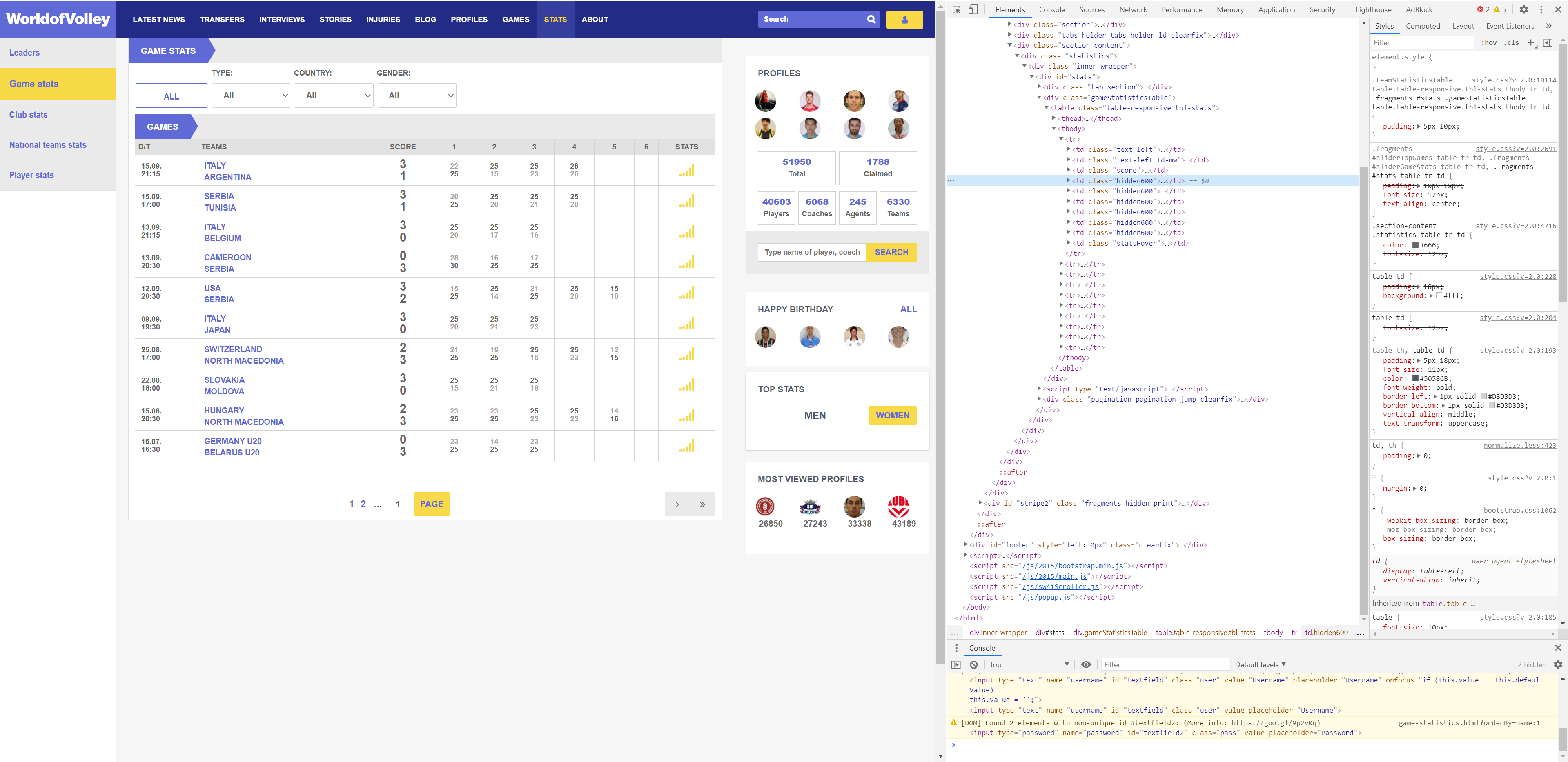
Step 1
Basically, we only need two libraries to scrape most of the websites: Requests and BeautifulSoup4. Install them first and load these two libraries.
# Install it first
! pip install requests
! pip install beautifulsoup4
# Load packages
import requests
from bs4 import BeautifulSoupWe use requests.get() method since we are sending a GET request to the specific url, in this case, to https://worldofvolley.com/statistics/game-statistics.html?orderBy=name.
# Install it first
url = "https://worldofvolley.com/statistics/game-statistics.html?orderBy=name"
source = requests.get(url)Step 2
BeautifulSoup is a Python library for pulling data out of HTML and XML files. HTML will look something like this:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>The HTML5 Herald</title>
<meta name="description" content="The HTML5 Herald">
<meta name="author" content="SitePoint">
<link rel="stylesheet" href="css/styles.css?v=1.0">
</head>
<body>
<script src="js/scripts.js"></script>
</body>
</html>Below is a simple illustration.
<tag attribute="value">Element content</tag>BeautifulSoup parses anything you give it, and does the tree traversal stuff for you.
soup = BeautifulSoup(source.text, "html.parser")If you do print(soup) and print(source), it looks the same, but the source is just plain the response data, and the soup is an object that we can actually interact with, by tag, now. Inside devtools subwindow, you can see that every rows of the data we need is inside <div id="stats">...</div> element.
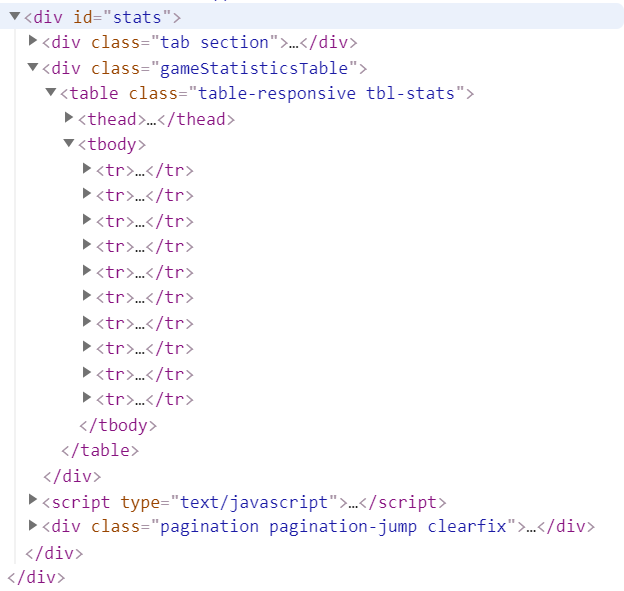
As you can see, there are exactly 10 rows of data in the table, also there are 10 <tr>...</tr> elements in devtool subwindow.
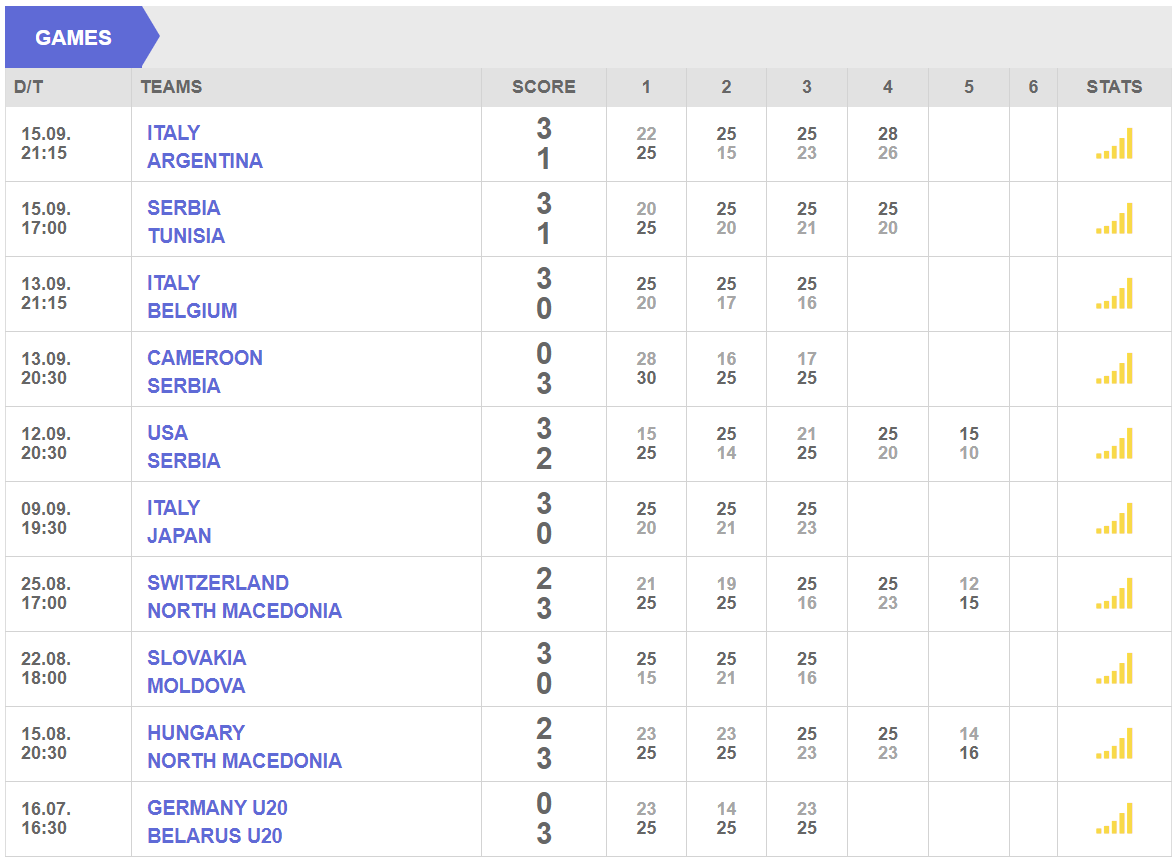
stats = soup.find("div", attrs={"id": "stats"})
table = stats.find("tbody")Right now, do print(table), Voila!
Step 3
In step 3, we need to iterate through every rows of them.
result = []
for row in table.find_all("tr"):
tds = row("td")
date = tds[0].find("span").text + tds[0].find("strong").text
contries = [x.strip() for x in tds[1].find_all(text=True) if x != "\n"]
scores = [x.strip() for x in tds[2].find_all(text=True) if x != "\n"]
set_1 = [x.strip() for x in tds[3].find_all(text=True) if x != "\n"]
set_2 = [x.strip() for x in tds[4].find_all(text=True) if x != "\n"]
set_3 = [x.strip() for x in tds[5].find_all(text=True) if x != "\n"]
set_4 = [x.strip() for x in tds[6].find_all(text=True) if x != "\n"]
set_5 = [x.strip() for x in tds[7].find_all(text=True) if x != "\n"]
result.append([date, contries, scores, set_1, set_2, set_3, set_4, set_5])Finding every texts inside tag <td> is a fairly common task. If we only want one element, we could use find() function to get what we want. In the case above, such as TEAMS row, there are two countries in the cell, what if we wanted to find them all? We could simply use find_all(text=True) function, this will get all the texts under each tds.
Finally, store the result inside a pandas DataFrame object.
import pandas as pd
columns = ["date", "contries", "scores", "set_1", "set_2", "set_3", "set_4", "set_5"]
data = pd.DataFrame(result, columns=columns)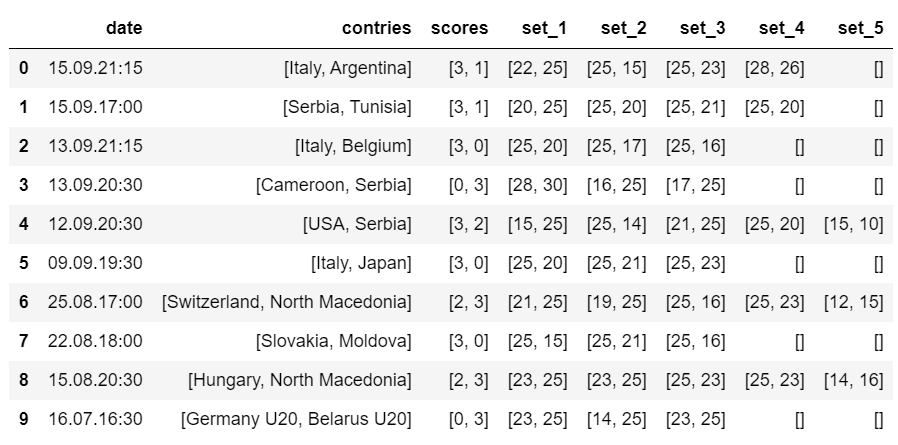
Save it to csv file:
data.to_csv("volley.csv", index=False)Or save it to database (I suppose you have a <database_name>.db file in your working directory).
def save_to_database(data, db_name="volley.db"):
database_path = f'sqlite:///data/{db_name}'
engine = create_engine(database_path, echo=False)
data.to_sql("volley", con=engine, if_exists='replace')
engine.dispose()
save_to_database(data, db_name="volley.db")Some Advance Tips
Fake a Browser Visit
Some of the developers of the website had made some blocks for people who wants to visit their webiste. One workaround is to provdie a user-agent header inside requests().
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
source = requests.get(url, headers=headers)Delays
It’s always good to put some delay between requests. In our case, we don’t need it if we only send our requests once. What if we need to scrape every pages on the website, then we probably need this.
from time import time
time.sleep(delay)Pull it All Together
class PyCrawler:
"""
Crawler for https://worldofvolley.com
Parameters
----------
pages: int
Total pages you want to crawl.
Returns
-------
data: pd.DataFrame
A pd.DataFrame contains "date", "contries", "scores", "set_1", "set_2", "set_3", "set_4", "set_5".
"""
def __init__(self, pages):
self.pages = pages
self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
def run(self):
dfs = []
for page in range(self.pages):
url = f"https://worldofvolley.com/statistics/game-statistics.html?orderBy=name&position={page}"
source = requests.get(url, headers=self.headers)
soup = BeautifulSoup(source.text, "html.parser")
stats = soup.find("div", attrs={"id": "stats"})
table = stats.find("tbody")
result = []
for row in table.find_all("tr"):
tds = row("td")
date = tds[0].find("span").text + tds[0].find("strong").text
contries = [x.strip() for x in tds[1].find_all(text=True) if x != "\n"]
scores = [x.strip() for x in tds[2].find_all(text=True) if x != "\n"]
set_1 = [x.strip() for x in tds[3].find_all(text=True) if x != "\n"]
set_2 = [x.strip() for x in tds[4].find_all(text=True) if x != "\n"]
set_3 = [x.strip() for x in tds[5].find_all(text=True) if x != "\n"]
set_4 = [x.strip() for x in tds[6].find_all(text=True) if x != "\n"]
set_5 = [x.strip() for x in tds[7].find_all(text=True) if x != "\n"]
result.append([date, contries, scores, set_1, set_2, set_3, set_4, set_5])
columns = ["date", "contries", "scores", "set_1", "set_2", "set_3", "set_4", "set_5"]
dfs.append(pd.DataFrame(result, columns=columns))
data = pd.concat(dfs)
return data
crawler = PyCrawler(pages=10)
data = crawler.run()
data.to_csv("volley.csv", index=False)Conclusion
If all goes well then that’s it! I hope it illustrated the basic concepts at work in building a web crawler. Perhaps now is a good time to step back and review your code!

