We just had a long Christmas vacation. It’s time to get back to study mode! Today I’m going to summarise some important point about weighted word embedding for some specific NLP tasks. Frankly speaking, this is the topic I wish to write about a few months ago, however, I was so busy during my MSc.
Load the Dataset
First things first, download IMDb dataset from HuggingFace’s Datasets library:
dataset = load_dataset("imdb")
def dataset_to_dataframe(dataset):
X_train, y_train = dataset["train"]["text"], dataset["train"]["label"]
X_test, y_test = dataset["test"]["text"], dataset["test"]["label"]
df_train = pd.DataFrame({
"text": X_train,
"label": y_train,
"tag": ["train"]*len(dataset["train"])
})
df_test = pd.DataFrame({
"text": X_test,
"label": y_test,
"tag": ["test"]*len(dataset["test"])
})
return df_train, df_testI tranformed the format into pd.DataFrame format.
dataset = load_dataset("imdb")
df_train, df_test = dataset_to_dataframe(dataset)
print("Shape of training data: {}".format(df_train.shape))
print("Shape of tesing data: {}".format(df_test.shape))There are 25000 samples for each training data and testing data.
Tokenisation
To tackle text related problem in NLP and ML area, tokenisation is one of the common pre-processing. There are various types of text processing techniques, such as lowercasing, stemming words, lemmetising words, and so on. In this article, I only went through handling work with tokenisation and lowercase.
There are many tools that support segmentation tool by all means, as I have listed below.
- English Segmentation Tools
- Chinese Segmentation Tools
- Japanese Segmentation Tools
I tokenised the sentence in the simplest way using regex.
def tokenization(text):
text = re.split('\W+', text)
return text
df_train["text_tokenised"] = df_train["text"].apply(lambda x: tokenization(x.lower()))
df_test["text_tokenised"] = df_test["text"].apply(lambda x: tokenization(x.lower()))Word Embedding Model
Word2Vec
Proposed by Tomas Mikolov et al. in their paper, there are two architectures (CBOW and Skip-gram) of word2vec to learn the underlying word representations for each word by using neural networks.
In the CBOW model, the distributed representations of context (or surrounding words) are combined to predict the word in the middle.

While in the Skip-gram model, the distributed representation of the input word is used to predict the context.
GloVe
GloVe is an unsupervised learning algorithm, proposed by Jeffrey Pennington et al., for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space. The paper shows that the model efficiently leverages statistical information by training only on the nonzero elements in a word-word cooccurrence matrix, rather than on the entire sparse matrix or on individual context
windows in a large corpus.
FastText
FastText is capable of building word vectors for words that do not appear in the training set. For such words, the authors simply average the vector representation of its n-grams. This shows that they build robust word representations where prefixes and suffixes can be ignored if the grammatical form is not found in the dictionary.
There are two application of FastText.
- Using for learning word representations: P. Bojanowski, et al., Enriching Word Vectors with Subword Information
- Using for text classification: A. Joulin, et al., Bag of Tricks for Efficient Text Classification
Load Pre-trained Model from Gensim
- Word2Vec pre-trained vectors download
- Unzip the file:
!gunzip ./GoogleNews-vectors-negative300.bin.gz
- Unzip the file:
- GloVe pre-trained vectors download
- Convert file into a gensim word2vec format:
glove2word2vec(glove_input_file=r"glove.840B.300d.txt", word2vec_output_file=r"gensim_glove_vectors.txt")
- Convert file into a gensim word2vec format:
- FastText pre-trained vectors download
- Convert file into a binary format:
embedding_dict = KeyedVectors.load_word2vec_format(r"cc.en.300.vec", binary=False) embedding_dict.save_word2vec_format(MODEL_PATH, binary=True)
- Convert file into a binary format:
While loading pre-trained model, you can grab a cup of tea or coffee, cause it will cost some time.
w2v_model = KeyedVectors.load_word2vec_format("GoogleNews-vectors-negative300.bin", binary=True)
glove_model = KeyedVectors.load_word2vec_format("gensim_glove_vectors.txt", binary=False)
ft_model = KeyedVectors.load_word2vec_format("cc.en.300.bin", binary=True)Weighted Method
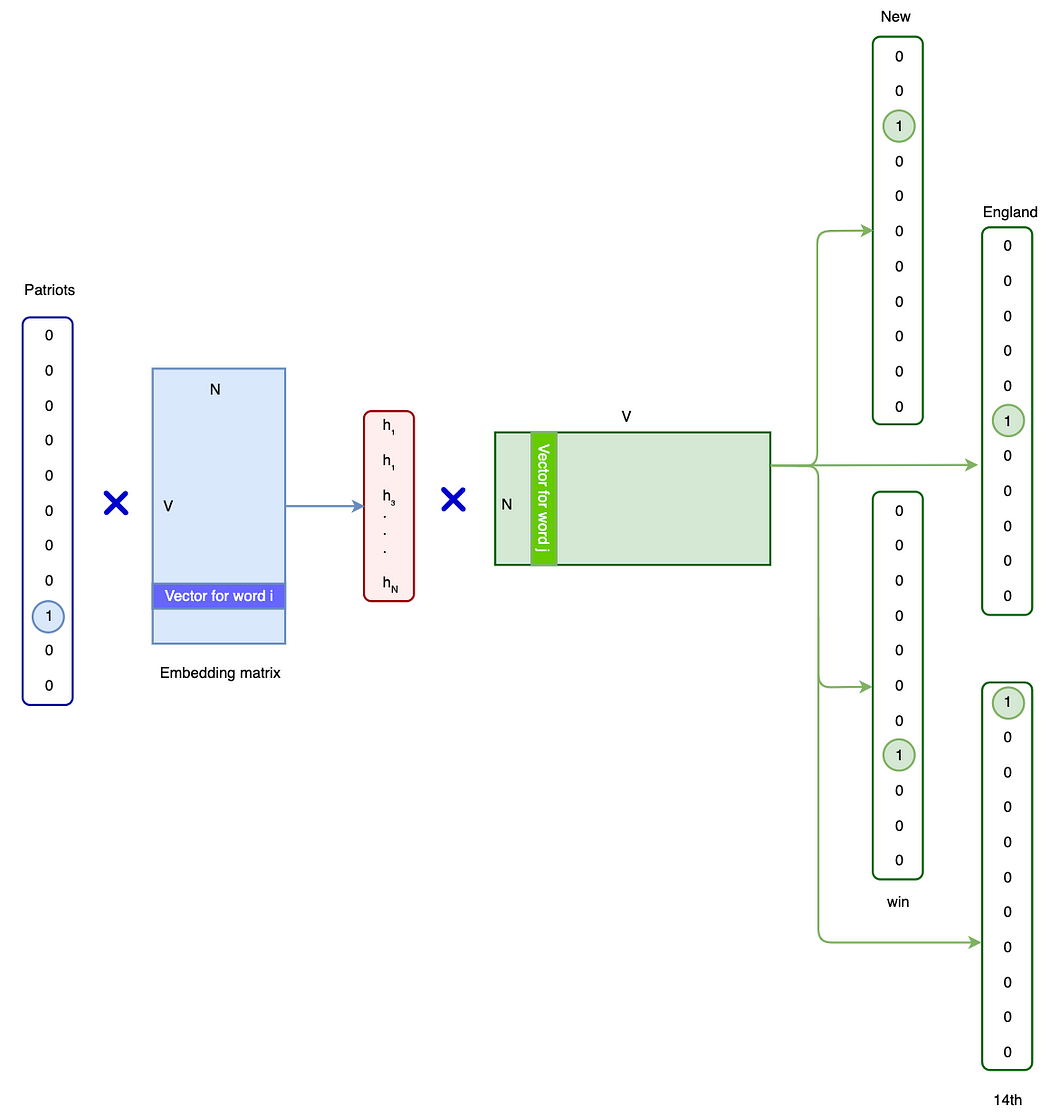
The aim of this section is to construct sentence embeddings, obtained from word embeddings. If the sentence
where
BoW
Averaging the component word vectors in every documents.
TFIDF
Term frequency–inverse document frequency (TF-IDF) is a popular method to capture the significance of a token to a particular input with respect to all the inputs.
is the tf-idf weight for term i in document j is number of time term i appear in document j is the total number of documents is the number of documents with token i
SIF
Instead of just averaging the component word vectors as suggested by this equation for BoW, SIF generate the sentence vector
Talk is Cheap, Show me the Code
class EmbeddingVectorizer(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self, X, y=None):
return self
def transform(self):
return X
def fit_transform(self, X, y=None):
self.fit(X, y)
def progressbar(self, iteration, prefix="", size=50, file=sys.stdout):
count = len(iteration)
def show(t):
x = int(size*t/count)
# file.write("%s[%s%s] %i/%i\r" % (prefix, "#"*x, "."*(size-x), int(100*t/count), 100))
file.write("{}[{}{}] {}%\r".format(prefix, "█"*x, "."*(size-x), int(100*t/count)))
file.flush()
show(0)
for i, item in enumerate(iteration):
yield item
show(i+1)
file.write("\n")
file.flush()
class MeanEmbeddingVectorizer(EmbeddingVectorizer):
"""
Parameters
----------
word2vec: gensim.models.KeyedVectors()
Word2Vec: https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz
GloVe: https://nlp.stanford.edu/projects/glove/
FastText: https://fasttext.cc/docs/en/crawl-vectors.html
Examples
--------
>>> from gensim.scripts import glove2word2vec
>>> from gensim.models import KeyedVectors
>>> w2v_model = KeyedVectors.load_word2vec_format("GoogleNews-vectors-negative300.bin", binary=True)
>>> glove2word2vec(glove_input_file=r"glove.840B.300d.txt", word2vec_output_file=r"gensim_glove_vectors.txt")
>>> glove_model = KeyedVectors.load_word2vec_format("gensim_glove_vectors.txt", binary=False)
>>> embedding_dict = KeyedVectors.load_word2vec_format(r"cc.en.300.vec", binary=False)
>>> embedding_dict.save_word2vec_format(r"cc.en.300.bin", binary=True)
>>> ft_model = KeyedVectors.load_word2vec_format("cc.en.300.bin", binary=True)
>>> vectoriser = MeanEmbeddingVectorizer(word2vec=w2v_model)
>>> feature = vectoriser.fit_transform(df["text"], None)
"""
def __init__(self, word2vec):
self.word2vec = word2vec
self.dim = word2vec.vector_size
def fit(self, X, y=None):
return self
def transform(self, X):
return np.array([
np.mean([self.word2vec[w] for w in words if w in self.word2vec]
or [np.zeros(self.dim)], axis=0)
for words in self.progressbar(X, prefix="Mean")
])
def fit_transform(self, X, y=None):
self.fit(X, y)
return self.transform(X)
def get_params(self, deep=True):
return {"word2vec": self.word2vec}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
class TfidfEmbeddingVectorizer(EmbeddingVectorizer):
"""
Parameters
----------
word2vec: gensim.models.KeyedVectors()
Word2Vec: https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz
GloVe: https://nlp.stanford.edu/projects/glove/
FastText: https://fasttext.cc/docs/en/crawl-vectors.html
use_idf: boolean
IDF stands for "Inverse Document Frequency", it is a measure of how much information
the word provide.
Examples
--------
>>> from gensim.scripts import glove2word2vec
>>> from gensim.models import KeyedVectors
>>> w2v_model = KeyedVectors.load_word2vec_format("GoogleNews-vectors-negative300.bin", binary=True)
>>> glove2word2vec(glove_input_file=r"glove.840B.300d.txt", word2vec_output_file=r"gensim_glove_vectors.txt")
>>> glove_model = KeyedVectors.load_word2vec_format("gensim_glove_vectors.txt", binary=False)
>>> embedding_dict = KeyedVectors.load_word2vec_format(r"cc.en.300.vec", binary=False)
>>> embedding_dict.save_word2vec_format(r"cc.en.300.bin", binary=True)
>>> ft_model = KeyedVectors.load_word2vec_format("cc.en.300.bin", binary=True)
>>> vectoriser = TfidfEmbeddingVectorizer(word2vec=w2v_model, use_idf=True)
>>> feature = vectoriser.fit_transform(df["text"], None)
"""
def __init__(self, word2vec, use_idf=True):
self.word2vec = word2vec
self.word2weight = None
self.use_idf = use_idf
self.dim = word2vec.vector_size
def word2tf(self, term_list):
term_freq = Counter(term_list)
total_len = sum(term_freq.values())
term_freq = [(term, term_freq[term]/total_len) for term, count in term_freq.items()]
return dict(term_freq)
def fit(self, X, y=None):
tfidf = TfidfVectorizer(analyzer=lambda x: x)
tfidf.fit(X)
max_idf = max(tfidf.idf_)
self.word2weight = defaultdict(
lambda: max_idf,
[(w, tfidf.idf_[i]) for w, i in tfidf.vocabulary_.items()])
return self
def transform(self, X):
transformed_X = []
for doc in self.progressbar(X, prefix="TF-IDF"):
weighted_array = []
for term in doc:
if term in self.word2vec:
if self.use_idf:
weighted_term = self.word2vec[term] * self.word2tf(doc)[term] * self.word2weight[term]
else:
weighted_term = self.word2vec[term] * self.word2tf(doc)[term]
weighted_array.append(weighted_term)
weighted_array = np.mean(weighted_array or [np.zeros(self.dim)], axis=0)
transformed_X.append(weighted_array)
return np.array(transformed_X)
def fit_transform(self, X, y=None):
self.fit(X, y)
return self.transform(X)
def get_params(self, deep=True):
return {"word2vec": self.word2vec, "use_idf": self.use_idf}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return self
class SifEmbeddingVectorizer(EmbeddingVectorizer):
"""
Parameters
----------
word2vec: gensim.models.KeyedVectors()
Word2Vec: https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz
GloVe: https://nlp.stanford.edu/projects/glove/
FastText: https://fasttext.cc/docs/en/crawl-vectors.html
smoothing_constant: float (default: 1e-3)
Default value of smoothing constant suggested in the paper is 0.001.
The range of a suggested in the paper: [1e−4, 1e−3]
Examples
--------
>>> from gensim.scripts import glove2word2vec
>>> from gensim.models import KeyedVectors
>>> w2v_model = KeyedVectors.load_word2vec_format("GoogleNews-vectors-negative300.bin", binary=True)
>>> glove2word2vec(glove_input_file=r"glove.840B.300d.txt", word2vec_output_file=r"gensim_glove_vectors.txt")
>>> glove_model = KeyedVectors.load_word2vec_format("gensim_glove_vectors.txt", binary=False)
>>> embedding_dict = KeyedVectors.load_word2vec_format(r"cc.en.300.vec", binary=False)
>>> embedding_dict.save_word2vec_format(r"cc.en.300.bin", binary=True)
>>> ft_model = KeyedVectors.load_word2vec_format("cc.en.300.bin", binary=True)
>>> vectoriser = SifEmbeddingVectorizer(word2vec=w2v_model)
>>> feature = vectoriser.fit_transform(df["text"], None)
"""
def __init__(self, word2vec, smoothing_constant=1e-3):
self.word2vec = word2vec
self.word2weight = None
self.dim = word2vec.vector_size
self.smoothing_constant = smoothing_constant
self.term_freq = None
def fit(self, X, y=None):
X_list = [item for sublist in X for item in sublist]
term_freq = Counter(X_list)
total_len = sum(term_freq.values())
term_freq = [(term, term_freq[term]/total_len) for term, count in term_freq.items()]
self.term_freq = dict(term_freq)
return self
def transform(self, X):
transformed_X = []
for doc in self.progressbar(X, prefix="SIF"):
weighted_array = []
for term in doc:
if term in self.word2vec:
# Compute smooth inverse frequency (SIF)
weight = self.smoothing_constant / (self.smoothing_constant + self.term_freq.get(term, 0))
weighted_term = self.word2vec[term] * weight
weighted_array.append(weighted_term)
weighted_array = np.mean(weighted_array or [np.zeros(self.dim)], axis=0)
transformed_X.append(weighted_array)
transformed_X = np.array(transformed_X)
# Common component removal: remove the projections of the average vectors on their first singular vector
svd = TruncatedSVD(n_components=1, n_iter=20, random_state=0)
svd.fit(transformed_X)
pc = svd.components_
transformed_X = transformed_X - transformed_X.dot(pc.T).dot(pc)
return transformed_X
def fit_transform(self, X, y=None):
self.fit(X, y)
return self.transform(X)
def get_params(self, deep=True):
return {"word2vec": self.word2vec, "smoothing_constant": self.smoothing_constant}
def set_params(self, **parameters):
for parameter, value in parameters.items():
setattr(self, parameter, value)
return selfAfter constructing all needed class for weighted word embedding, next step is to see which combination of the embedding method performs the best.
# Word2Vec
vectoriser_w2v_mean = MeanEmbeddingVectorizer(word2vec=w2v_model)
feature_train_w2v_mean = vectoriser_w2v_mean.fit_transform(df_train["text_tokenised"], None)
vectoriser_w2v_tfidf = TfidfEmbeddingVectorizer(word2vec=w2v_model)
feature_train_w2v_tfidf = vectoriser_w2v_tfidf.fit_transform(df_train["text_tokenised"], None)
vectoriser_w2v_sif = SifEmbeddingVectorizer(word2vec=w2v_model)
feature_train_w2v_sif = vectoriser_w2v_sif.fit_transform(df_train["text_tokenised"], None)# GloVe
vectoriser_glove_mean = MeanEmbeddingVectorizer(word2vec=glove_model)
feature_train_glove_mean = vectoriser_glove_mean.fit_transform(df_train["text_tokenised"], None)
vectoriser_glove_tfidf = TfidfEmbeddingVectorizer(word2vec=glove_model)
feature_train_glove_tfidf = vectoriser_glove_tfidf.fit_transform(df_train["text_tokenised"], None)
vectoriser_glove_sif = SifEmbeddingVectorizer(word2vec=glove_model)
feature_train_glove_sif = vectoriser_glove_sif.fit_transform(df_train["text_tokenised"], None)# FastText
vectoriser_ft_mean = MeanEmbeddingVectorizer(word2vec=ft_model)
feature_train_ft_mean = vectoriser_ft_mean.fit_transform(df_train["text_tokenised"], None)
vectoriser_ft_tfidf = TfidfEmbeddingVectorizer(word2vec=ft_model)
feature_train_ft_tfidf = vectoriser_ft_tfidf.fit_transform(df_train["text_tokenised"], None)
vectoriser_ft_sif = SifEmbeddingVectorizer(word2vec=ft_model)
feature_train_ft_sif = vectoriser_ft_sif.fit_transform(df_train["text_tokenised"], None)I stored these into dictionaries.
vectorisers = {
"word2vec": {
"mean": vectoriser_w2v_mean,
"tfidf": vectoriser_w2v_tfidf,
"sif": vectoriser_w2v_sif
},
"glove": {
"mean": vectoriser_glove_mean,
"tfidf": vectoriser_glove_tfidf,
"sif": vectoriser_glove_sif
},
"fasttext": {
"mean": vectoriser_ft_mean,
"tfidf": vectoriser_ft_tfidf,
"sif": vectoriser_ft_sif
}
}
features = {
"word2vec": {
"mean": feature_train_w2v_mean,
"tfidf": feature_train_w2v_tfidf,
"sif": feature_train_w2v_sif
},
"glove": {
"mean": feature_train_glove_mean,
"tfidf": feature_train_glove_tfidf,
"sif": feature_train_glove_sif
},
"fasttext": {
"mean": feature_train_ft_mean,
"tfidf": feature_train_ft_tfidf,
"sif": feature_train_ft_sif
}
}Build Models
Finally, we could test it with machine learning model!
Define a cross validation function cross_val() to prevent models from overfitting.
def cross_val(Xtrain, ytrain, clf, cv=10, verbose=False):
best_clf = None
best_score = 0.0
num_folds = 0
cv_scores = []
kfold = KFold(n_splits=cv)
for train, val in kfold.split(Xtrain):
Xctrain, Xctest, yctrain, yctest = Xtrain[train], Xtrain[val], ytrain[train], ytrain[val]
clf.fit(Xctrain, yctrain)
score = clf.score(Xctest, yctest)
if score > best_score:
best_score = score
best_clf = clf
if verbose:
print("Fold {:d}: score: {:.4f}".format(num_folds, score))
cv_scores.append(score)
num_folds += 1
return best_clf, cv_scores
def test_eval(Xtest, ytest, clf):
print("Test set results")
ytest_ = clf.predict(Xtest)
accuracy = accuracy_score(ytest, ytest_)
print("Accuracy: {:.4f}".format(accuracy))Let the training begin!
results = defaultdict(dict)
for embedding in ["word2vec", "glove", "fasttext"]:
for weighting in ["mean", "tfidf", "sif"]:
print(f"Training with {embedding}-{weighting} model...")
clf = xgboost.XGBClassifier(n_estimators=300, max_depth=5)
clf, cv_scores = cross_val(features[embedding][weighting], df_train.label.values, clf, verbose=False)
results[f"{embedding}-{weighting}"]["classifer"] = clf
results[f"{embedding}-{weighting}"]["cv_result"] = cv_scores
print("Done with training model!")You can also play around with putting these customised functions in Scikit-Learn pipeline. We have seen that some estimators can transform data and that some estimators can predict variables. We can also create combined estimators like the following:
pca = PCA()
logistic = LogisticRegression(max_iter=10000, tol=0.1)
pipe = Pipeline(steps=[("word2vec vectorizer (tfidf)", TfidfEmbeddingVectorizer(w2v_model)),
('pca', pca),
('logistic', logistic)], verbose=1)
# Parameters of pipelines can be set using ‘__’ separated parameter names:
param_grid = {
'pca__n_components': [4, 8, 16, 32, 64, 128]
}
search = GridSearchCV(pipe, param_grid, n_jobs=8, cv=StratifiedKFold(n_splits=3, shuffle=True, random_state=42))
search.fit(X_train, y_train)Plot the PCA specturm.
X_embed = TfidfEmbeddingVectorizer(w2v_model).fit_transform(X_train, None)
pca.fit(X_embed)
fig, (ax0, ax1) = plt.subplots(nrows=2, sharex=True, figsize=(15, 6))
ax0.plot(np.arange(1, pca.n_components_ + 1),
pca.explained_variance_ratio_, '+', linewidth=2)
ax0.set_ylabel('PCA explained variance ratio')
ax0.axvline(search.best_estimator_.named_steps['pca'].n_components,
linestyle=':', label='N Components Chosen')
ax0.legend(prop=dict(size=12), loc="upper right")
ax0.grid()
# For each number of components, find the best classifier results
results = pd.DataFrame(search.cv_results_)
components_col = 'param_pca__n_components'
best_clfs = results.groupby(components_col).apply(
lambda g: g.nlargest(1, 'mean_test_score'))
best_clfs.plot(x=components_col, y='mean_test_score', yerr='std_test_score',
legend=False, ax=ax1)
ax1.set_ylabel('Classification accuracy (val)')
ax1.set_xlabel('N Components')
ax1.grid()
plt.xlim(-1, 130)
plt.tight_layout()
plt.show()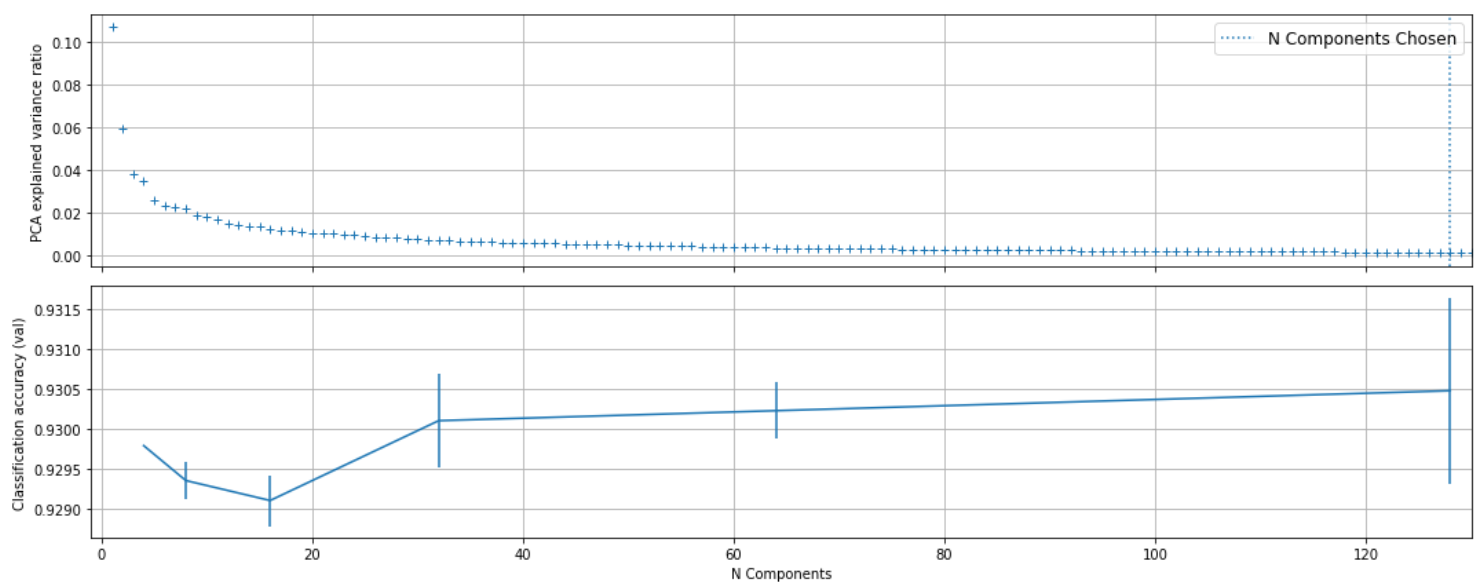
Perfomance
Some algorithms favor simple averaging, some algorithms perform better with TF-IDF weighting. Let’s see what’s the best in this text classification task.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15, 6))
plt.boxplot([c[1] for c in cv_list], labels=[c[0] for c in cv_list], showmeans=True)
plt.show()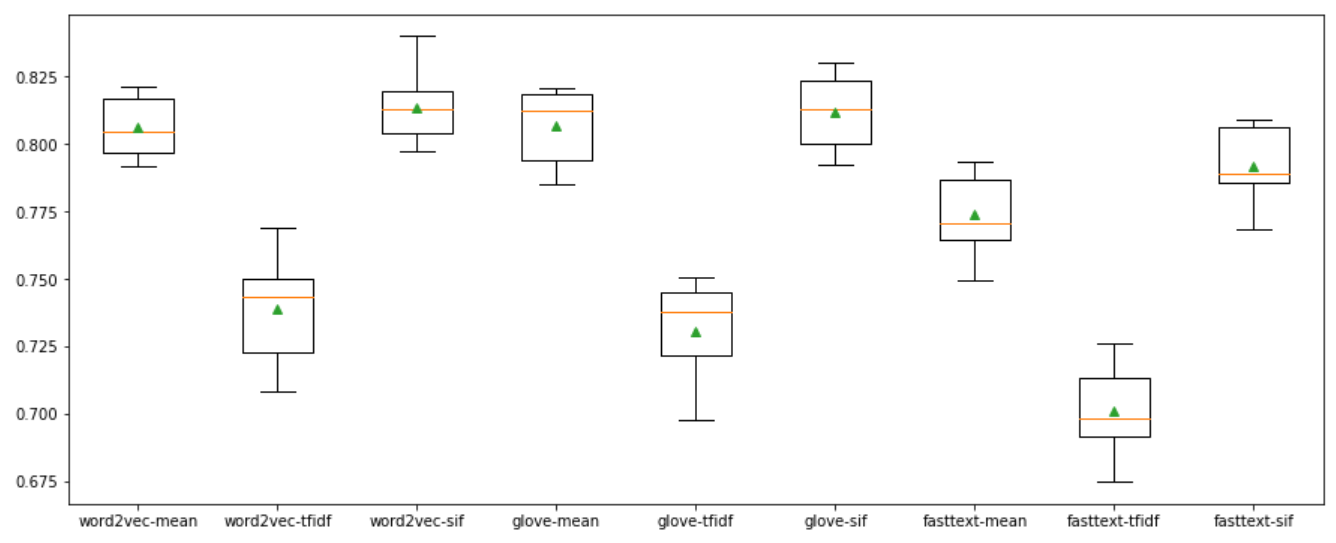
Conclusion
Distributed representation of word is an interesting field that is actively studied. Furthermore, it can be applied to many downstream tasks and real-life application. I hope this article will help you understand the basic concept of word embedding. I have been posting information and tutorials on my GitHub, if you are interested in these fields, PLEASE FOLLOW ME!!!
References
- https://www.kaggle.com/reiinakano/basic-nlp-bag-of-words-tf-idf-word2vec-lstm
- http://nadbordrozd.github.io/blog/2016/05/20/text-classification-with-word2vec/
- https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/
- https://jonathan-hui.medium.com/nlp-word-embedding-glove-5e7f523999f6

