The objective of this task is to detect hate speech in tweets. For the sake of simplicity, let’s say a tweet contains hate speech if it has a racist or sexist sentiment associated with it. So, the task is to classify racist or sexist tweets from other tweets.
Introduction
Hate speech is an unfortunately common occurrence on the Internet. Often social media sites like Facebook and Twitter face the problem of identifying and censoring problematic posts while weighing the right to freedom of speech. The importance of detecting and moderating hate speech is evident from the strong connection between hate speech and actual hate crimes. Early identification of users promoting hate speech could enable outreach programs that attempt to prevent an escalation from speech to action. Sites such as Twitter and Facebook have been seeking to actively combat hate speech. In spite of these reasons, NLP research on hate speech has been very limited, primarily due to the lack of a general definition of hate speech, an analysis of its demographic influences, and an investigation of the most effective features.
Formally, given a training sample of tweets and labels, where label ‘1’ denotes the tweet is racist/sexist and label ‘0’ denotes the tweet is not racist/sexist, our objective is to predict the labels on the test dataset.
Import Libraries
Let’s import the packages we need.
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
import re
import string
import swifter
import nltk
import random
import tez
import transformers
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud, STOPWORDS
from transformers import AdamW, get_linear_schedule_with_warmup
from sklearn import metrics, model_selection, preprocessing
from tez.callbacks import EarlyStopping
from tez.callbacks import CallbackRunner
from tez import enums
from tez.utils import AverageMeter
from torch.utils.data import Dataset
from torch.nn import functional as F
from collections import defaultdict
from collections import Counter
from tqdm import tqdmSet the random seed, it’s useful for reproducing the issues.
def seed_everything(seed=914):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
seed_everything()Some util functions refered from here.
def threshold_search(y_true, y_proba):
best_threshold = 0
best_score = 0
for threshold in tqdm([i * 0.01 for i in range(100)], disable=True):
score = metrics.f1_score(y_true=y_true, y_pred=y_proba > threshold)
if score > best_score:
best_threshold = threshold
best_score = score
search_result = {'threshold': best_threshold, 'f1': best_score}
return search_resultConfigurations
class DictObj(object):
def __init__(self, dictionary):
import pprint
self.map = dictionary
pprint.pprint(dictionary)
def __setattr__(self, name, value):
if name == 'map':
# print("init set attr", name ,"value:", value)
object.__setattr__(self, name, value)
return
# print('set attr called ', name, value)
self.map[name] = value
def __getattr__(self, name):
# print('get attr called ', name)
return self.map[name]
PARAM = DictObj({
'NUM_CLASSES': 2,
'MAX_LENGTH': 256,
'TRAIN_BATCH_SIZE': 8,
'VALID_BATCH_SIZE': 16,
'EPOCH': 5,
'DEVICE': "cuda",
'N_JOB': 0,
'FP16': True,
'ES_PATIENCE': 10,
'TF_LOG': "./logs/",
'MODEL_SAVE_PATH': "./models/bert.bin"
})EDA
Load the data.
dfx = pd.read_csv("./data/train.csv")Visualise the wordcloud. You can download the font from here.
more_stopwords = {
'oh', 'will', 'hey', 'yet', 'ye', 'really',
'make', 'amp', 'via', 'ð', '¼', 'â'}
STOPWORDS = STOPWORDS.union(more_stopwords)
corpus = ' '.join(dfx['tweet'])
no_urls_no_tags = " ".join([word for word in corpus.split()
if 'http' not in word
and not word.startswith('@')
and not word.startswith('#')
and word != 'RT'
])
wordcloud = WordCloud(
font_path=r"CabinSketch-Bold.ttf",
stopwords=STOPWORDS,
background_color='black',
width=2500,
height=1400
).generate(no_urls_no_tags)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
Clean the data.
nltk.download('words')
words = set(nltk.corpus.words.words())
def clean_tweets(text):
text = strip_links(text)
text = strip_all_entities(text)
text = strip_non_english_words(text)
return text
def strip_links(text):
link_regex = re.compile('((https?):((//)|(\\\\))+([\w\d:#@%/;$()~_?\+-=\\\.&](#!)?)*)', re.DOTALL)
links = re.findall(link_regex, text)
for link in links:
text = text.replace(link[0], '[LINK]')
return text
def strip_all_entities(text):
entity_prefixes = ['@', '#']
for separator in string.punctuation.replace("[", "").replace("]", ""):
if separator not in entity_prefixes:
text = text.replace(separator,' ')
words = []
for word in text.split():
word = word.strip()
if word:
if word[0] not in entity_prefixes:
words.append(word)
return ' '.join(words)
def strip_non_english_words(text):
return text.encode('ascii', errors='ignore').decode("ascii", errors="ignore")
dfx["review"] = dfx["tweet"].swifter.apply(clean_tweets)
dfx["length"] = dfx["review"].swifter.apply(len)
dfx = dfx.drop(dfx[dfx.length < 10].index)
dfx = dfx.reset_index(drop=True)Split the data.
df_train, df_valid = model_selection.train_test_split(
dfx, test_size=0.2, random_state=42, stratify=dfx.label.values
)
df_train = df_train.reset_index(drop=True)
df_valid = df_valid.reset_index(drop=True)Calculate weight for imbalanced dataset.
class_sample_count = np.array([len(np.where(df_train.label==t)[0]) for t in np.unique(df_train.label)])
weight = 1. / class_sample_count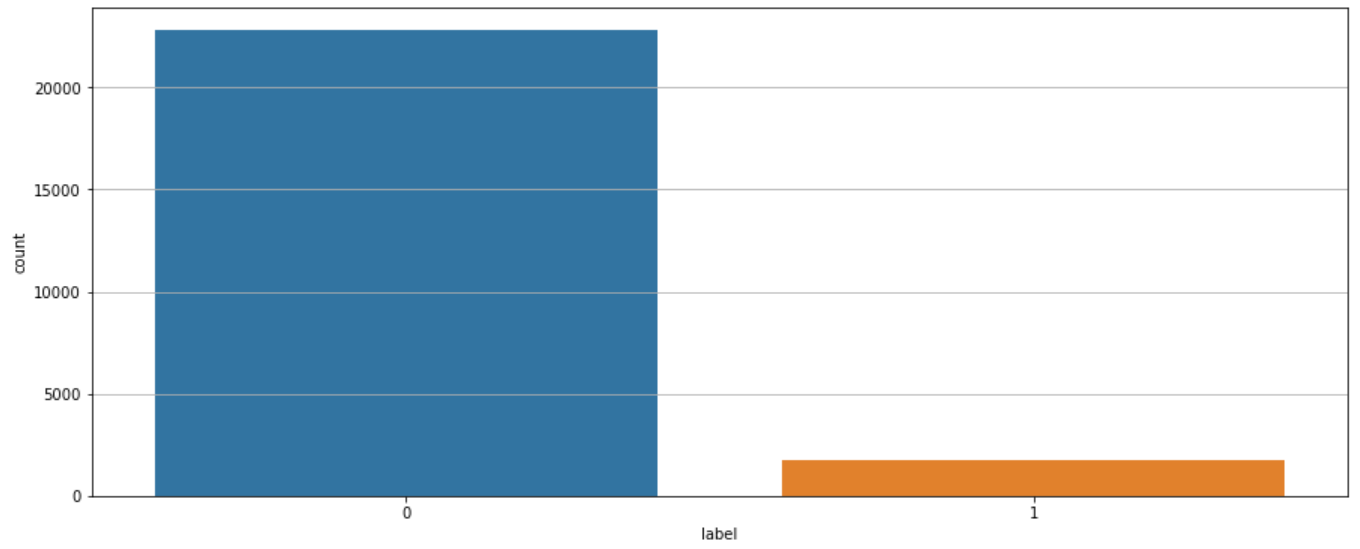
Dataset
Let’s create a Dataset() class for our twitter hate speech dataset.
class TwitterDataset(Dataset):
def __init__(self, review, target, max_len=64):
self.review = review
self.target = target
self.tokenizer = transformers.BertTokenizer.from_pretrained(
"bert-base-uncased", do_lower_case=True
)
self.max_len = max_len
def __len__(self):
return len(self.review)
def __getitem__(self, item):
review = str(self.review[item])
review = " ".join(review.split())
inputs = self.tokenizer.encode_plus(
review,
None,
add_special_tokens=True,
max_length=self.max_len,
padding="max_length",
truncation=True,
return_tensors='pt',
)
input_ids = inputs["input_ids"].flatten()
attention_mask = inputs["attention_mask"].flatten()
return {
"ids": input_ids,
"mask": attention_mask,
"targets": torch.tensor(self.target[item], dtype=torch.long)
}
train_dataset = TwitterDataset(df_train.review.values, df_train.label.values, max_len=PARAM.MAX_LENGTH)
valid_dataset = TwitterDataset(df_valid.review.values, df_valid.label.values, max_len=PARAM.MAX_LENGTH)We have 24575 training data and 6144 validation data.
Model
I will use Tez, a simple pytorch trainer, to build our neural network. Tez is a simple, to-the-point, library to make your pytorch training easy.
class TwitterClassifier(tez.Model):
def __init__(self, num_train_steps, num_classes, weight=None, optimizer="lamb"):
super().__init__()
self.tokenizer = transformers.BertTokenizer.from_pretrained(
"bert-base-uncased", do_lower_case=True
)
self.bert = transformers.BertModel.from_pretrained(
"bert-base-uncased",
return_dict=False)
self.bert_drop = nn.Dropout(0.3)
self.out = nn.Linear(self.bert.config.hidden_size, num_classes)
self.num_train_steps = num_train_steps
self.step_scheduler_after = "batch"
self.optimizer = optimizer
self.history = defaultdict(list)
if weight is not None:
self.weight = torch.tensor(weight).float()
def fetch_optimizer(self):
param_optimizer = list(self.named_parameters())
no_decay = ["bias", "LayerNorm.bias"]
optimizer_parameters = [
{
"params": [
p for n, p in param_optimizer if not any(nd in n for nd in no_decay)
],
"weight_decay": 0.001,
},
{
"params": [
p for n, p in param_optimizer if any(nd in n for nd in no_decay)
],
"weight_decay": 0.0,
},
]
if self.optimizer == "adam":
opt = AdamW(optimizer_parameters, lr=3e-5)
elif self.optimizer == "lamb":
opt = Lamb(optimizer_parameters, lr=3e-5, weight_decay=.01, betas=(.9, .999))
return opt
def fetch_scheduler(self):
sch = get_linear_schedule_with_warmup(
self.optimizer, num_warmup_steps=0, num_training_steps=self.num_train_steps
)
return sch
def train_one_epoch(self, data_loader):
self.train()
self.model_state = enums.ModelState.TRAIN
losses = AverageMeter()
tk0 = tqdm(data_loader, total=len(data_loader))
for b_idx, data in enumerate(tk0):
self.train_state = enums.TrainingState.TRAIN_STEP_START
loss, metrics = self.train_one_step(data)
self.train_state = enums.TrainingState.TRAIN_STEP_END
losses.update(loss.item(), data_loader.batch_size)
if b_idx == 0:
metrics_meter = {k: AverageMeter() for k in metrics}
monitor = {}
for m_m in metrics_meter:
metrics_meter[m_m].update(metrics[m_m], data_loader.batch_size)
monitor[m_m] = metrics_meter[m_m].avg
self.current_train_step += 1
tk0.set_postfix(loss=losses.avg, stage="train", **monitor)
tk0.close()
self.update_metrics(losses=losses, monitor=monitor)
for k, v in monitor.items():
self.history[f"train_{k}"].append(v)
self.history["train_loss"].append(losses.avg)
return losses.avg
def validate_one_epoch(self, data_loader):
self.eval()
self.model_state = enums.ModelState.VALID
losses = AverageMeter()
tk0 = tqdm(data_loader, total=len(data_loader))
for b_idx, data in enumerate(tk0):
self.train_state = enums.TrainingState.VALID_STEP_START
with torch.no_grad():
loss, metrics = self.validate_one_step(data)
self.train_state = enums.TrainingState.VALID_STEP_END
losses.update(loss.item(), data_loader.batch_size)
if b_idx == 0:
metrics_meter = {k: AverageMeter() for k in metrics}
monitor = {}
for m_m in metrics_meter:
metrics_meter[m_m].update(metrics[m_m], data_loader.batch_size)
monitor[m_m] = metrics_meter[m_m].avg
tk0.set_postfix(loss=losses.avg, stage="valid", **monitor)
self.current_valid_step += 1
tk0.close()
self.update_metrics(losses=losses, monitor=monitor)
for k, v in monitor.items():
self.history[f"valid_{k}"].append(v)
self.history["valid_loss"].append(losses.avg)
return losses.avg
def loss(self, outputs, targets):
if targets is None:
return None
if self.weight is not None:
self.weight = self.weight.to(self.device)
return nn.CrossEntropyLoss(self.weight)(outputs, targets)
def monitor_metrics(self, outputs, targets):
if targets is None:
return {}
outputs = torch.argmax(outputs, dim=1).cpu().detach().numpy()
targets = targets.cpu().detach().numpy()
accuracy = metrics.accuracy_score(targets, outputs)
f1_score = metrics.f1_score(targets, outputs, average='weighted')
return {"accuracy": accuracy, "f1": f1_score}
def forward(self, ids, mask, targets=None):
last_hidden_states = self.bert(ids, attention_mask=mask)
b_o = self.bert_drop(last_hidden_states[0][:, 0, :])
output = self.out(b_o)
loss = self.loss(output, targets)
acc = self.monitor_metrics(output, targets)
return output, loss, acc
def score(self, test_dataset, n_jobs=0):
def softmax(x):
return np.exp(x) / np.sum(np.exp(x), axis=0)
prediction = self.predict(test_dataset, n_jobs=n_jobs)
prediction = list(prediction)
prediction = softmax(np.vstack(prediction))
prediction = np.argmax(prediction, axis=1)
groud_truth = test_dataset[:]["target"].detach().numpy().astype(np.int64)
return metrics.accuracy_score(prediction, groud_truth)
def plot_history(self):
from matplotlib.ticker import MaxNLocator
train_loss, valid_loss = self.history["train_loss"], self.history["valid_loss"]
train_accuracy, valid_accuracy = self.history["train_accuracy"], self.history["valid_accuracy"]
plt.rcParams["figure.figsize"] = 15, 6
ax1 = plt.subplot(2, 1, 1)
ax1.plot(range(1, len(train_loss)+1), train_loss, color="tab:blue", label="train")
ax1.plot(range(1, len(valid_loss)+1), valid_loss, color="tab:orange", label="valid")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True))
ax1.title.set_text('Loss')
ax1.grid()
ax2 = plt.subplot(2, 1, 2)
ax2.plot(range(1, len(train_accuracy)+1), train_accuracy, color="tab:blue", label="train")
ax2.plot(range(1, len(valid_accuracy)+1), valid_accuracy, color="tab:orange", label="valid")
ax2.xaxis.set_major_locator(MaxNLocator(integer=True))
ax2.title.set_text('Accuracy')
ax2.grid()
plt.tight_layout()
plt.show()Training large deep neural networks on massive datasets is computationally very
challenging. In Yang You’s paper, they first study a principled layerwise adaptation strategy to accelerate training of deep neural networks using large mini-batches. Using this strategy, they develop a new layerwise adaptive large batch optimization technique called LAMB. The LAMB implementation is available online.
class Lamb(torch.optim.Optimizer):
r"""Implements Lamb algorithm.
It has been proposed in `Large Batch Optimization for Deep Learning: Training BERT in 76 minutes`_.
Arguments:
params (iterable): iterable of parameters to optimize or dicts defining
parameter groups
lr (float, optional): learning rate (default: 1e-3)
betas (Tuple[float, float], optional): coefficients used for computing
running averages of gradient and its square (default: (0.9, 0.999))
eps (float, optional): term added to the denominator to improve
numerical stability (default: 1e-8)
weight_decay (float, optional): weight decay (L2 penalty) (default: 0)
adam (bool, optional): always use trust ratio = 1, which turns this into
Adam. Useful for comparison purposes.
.. _Large Batch Optimization for Deep Learning: Training BERT in 76 minutes:
https://arxiv.org/abs/1904.00962
"""
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-6,
weight_decay=0, adam=False):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay)
self.adam = adam
super(Lamb, self).__init__(params, defaults)
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data
if grad.is_sparse:
raise RuntimeError('Lamb does not support sparse gradients, consider SparseAdam instad.')
state = self.state[p]
# State initialization
if len(state) == 0:
state['step'] = 0
# Exponential moving average of gradient values
state['exp_avg'] = torch.zeros_like(p.data)
# Exponential moving average of squared gradient values
state['exp_avg_sq'] = torch.zeros_like(p.data)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
state['step'] += 1
# Decay the first and second moment running average coefficient
# m_t
exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
# v_t
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
# Paper v3 does not use debiasing.
# bias_correction1 = 1 - beta1 ** state['step']
# bias_correction2 = 1 - beta2 ** state['step']
# Apply bias to lr to avoid broadcast.
step_size = group['lr'] # * math.sqrt(bias_correction2) / bias_correction1
weight_norm = p.data.pow(2).sum().sqrt().clamp(0, 10)
adam_step = exp_avg / exp_avg_sq.sqrt().add(group['eps'])
if group['weight_decay'] != 0:
adam_step.add_(p.data, alpha=group['weight_decay'])
adam_norm = adam_step.pow(2).sum().sqrt()
if weight_norm == 0 or adam_norm == 0:
trust_ratio = 1
else:
trust_ratio = weight_norm / adam_norm
state['weight_norm'] = weight_norm
state['adam_norm'] = adam_norm
state['trust_ratio'] = trust_ratio
if self.adam:
trust_ratio = 1
p.data.add_(adam_step, alpha=-step_size * trust_ratio)
return lossStart Training!
n_train_steps = int(len(df_train) / 32 * 10)
model = TwitterClassifier(num_train_steps=n_train_steps, num_classes=PARAM.NUM_CLASSES, weight=weight)
tb_logger = tez.callbacks.TensorBoardLogger(log_dir=PARAM.TF_LOG)
es = tez.callbacks.EarlyStopping(monitor="valid_loss",
model_path=PARAM.MODEL_SAVE_PATH,
patience=PARAM.ES_PATIENCE)
model.fit(
train_dataset,
valid_dataset=valid_dataset,
train_bs=PARAM.TRAIN_BATCH_SIZE,
valid_bs=PARAM.VALID_BATCH_SIZE,
device=PARAM.DEVICE,
epochs=PARAM.EPOCH,
callbacks=[tb_logger, es],
n_jobs=PARAM.N_JOB,
fp16=PARAM.FP16,
)
model.save(PARAM.MODEL_SAVE_PATH)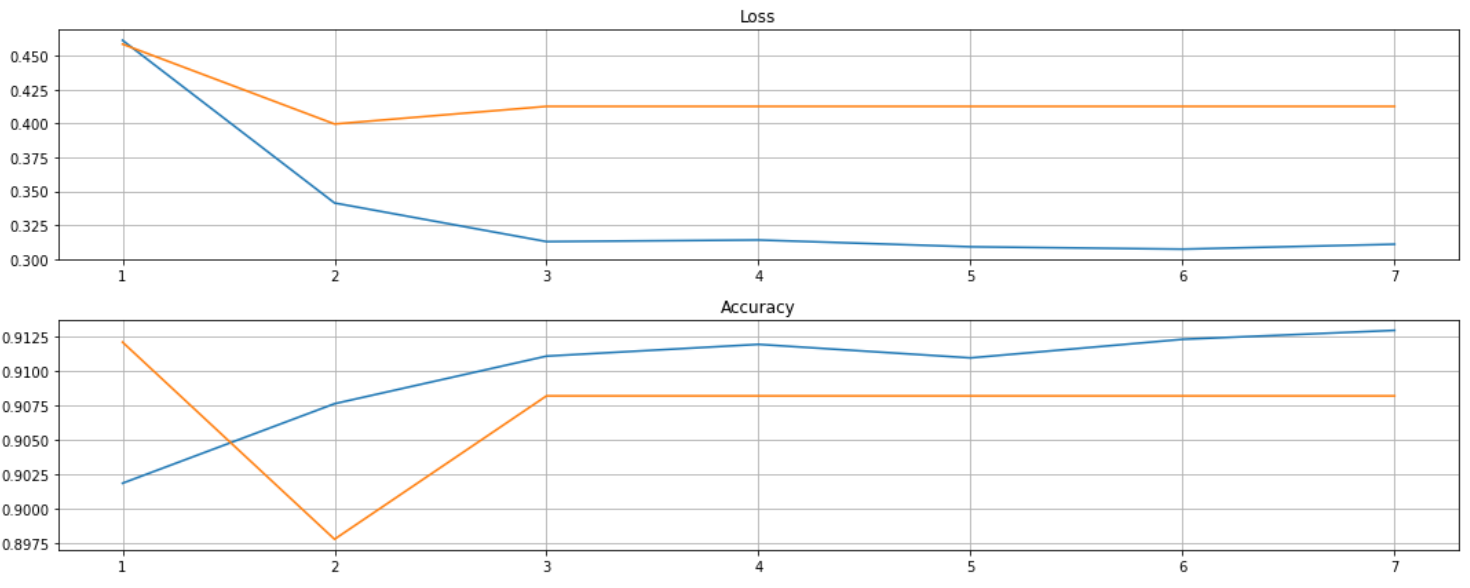
Inference
class TwitterInferenceClassifier(tez.Model):
def __init__(self, num_classes):
super().__init__()
self.tokenizer = transformers.BertTokenizer.from_pretrained(
"bert-base-uncased", do_lower_case=True
)
self.bert = transformers.BertModel.from_pretrained(
"bert-base-uncased",
return_dict=False)
self.bert_drop = nn.Dropout(0.3)
self.out = nn.Linear(self.bert.config.hidden_size, num_classes)
def forward(self, ids, mask, targets=None):
last_hidden_states = self.bert(ids, attention_mask=mask)
b_o = self.bert_drop(last_hidden_states[0][:, 0, :])
output = self.out(b_o)
return output, _, _
def load(self, model_path, device="cuda"):
self.device = device
if next(self.parameters()).device != self.device:
self.to(self.device)
model_dict = torch.load(model_path, map_location=torch.device(device))
self.load_state_dict(model_dict["state_dict"])
model_reload = TwitterInferenceClassifier(num_classes=2).to(PARAM.DEVICE)
model_reload.load(PARAM.MODEL_SAVE_PATH, device=PARAM.DEVICE)
test_df["review"] = test_df["tweet"].swifter.apply(clean_tweets)
test_df["length"] = test_df["review"].swifter.apply(len)
test_df["label"] = 0
test_dataset = TwitterDataset(test_df.review.values, test_df.label.values, max_len=PARAM.MAX_LENGTH)
def softmax(x):
return np.exp(x) / np.sum(np.exp(x), axis=0)
prediction = model_reload.predict(test_dataset, n_jobs=0, batch_size=8)
prediction = list(prediction)
prediction = softmax(np.vstack(prediction))
prediction = np.argmax(prediction, axis=1)
submit = pd.read_csv("./data/sample_submission.csv")
submit["label"] = prediction
submit.to_csv("./data/submit.csv", index=False)This solution to the detection of hate speech and offensive language on Twitter through deep learning using BERT achieves reasonable accuracy (90.8%) as well as f1-score (92.1%) on validation dataset. However, it got low f1-score (29.5%) on test dataset. As we can see, the high accuracy rate was just an illusion.
Supervised learning relies on the fact that training and test data follow the same distribution. If that were not the case, then one could perfectly get a model that performs well in training data but does not on test data. And it would not be because of overfitting of the training data.
First, let’s try to reduce the complexity of the model.
Naive Bayes Classifier
We’ll take a look at one natural language processing technique for text classification called Naive Bayes.
import os
import re
import string
import math
target_names = ['non-toxic', 'toxic']
class HateSpeechDetector(object):
def clean(self, s):
translator = str.maketrans("", "", string.punctuation)
return s.translate(translator)
def tokenize(self, text):
text = self.clean(text).lower()
return re.split("\W+", text)
def get_word_counts(self, words):
word_counts = {}
for word in words:
word_counts[word] = word_counts.get(word, 0.0) + 1.0
return word_counts
def fit(self, X, Y):
self.num_reviews = {}
self.log_class_priors = {}
self.word_counts = {}
self.vocab = set()
n = len(X)
self.num_reviews['toxic'] = sum(1 for label in Y if label == 1)
self.num_reviews['non-toxic'] = sum(1 for label in Y if label == 0)
self.log_class_priors['toxic'] = math.log(self.num_reviews['toxic'] / n)
self.log_class_priors['non-toxic'] = math.log(self.num_reviews['non-toxic'] / n)
self.word_counts['toxic'] = {}
self.word_counts['non-toxic'] = {}
for x, y in zip(X, Y):
c = 'toxic' if y == 1 else 'non-toxic'
counts = self.get_word_counts(self.tokenize(x))
for word, count in counts.items():
if word not in self.vocab:
self.vocab.add(word)
if word not in self.word_counts[c]:
self.word_counts[c][word] = 0.0
self.word_counts[c][word] += count
def predict(self, X):
result = []
for x in X:
counts = self.get_word_counts(self.tokenize(x))
toxic_score = 0
non_toxic_score = 0
for word, _ in counts.items():
if word not in self.vocab: continue
# Add Laplace smoothing
log_w_given_toxic = math.log(
(self.word_counts['toxic'].get(word, 0.0)+1)/(self.num_reviews['toxic']+len(self.vocab)))
log_w_given_non_toxic = math.log(
(self.word_counts['non-toxic'].get(word, 0.0)+1)/(self.num_reviews['non-toxic']+len(self.vocab)))
toxic_score += log_w_given_toxic
non_toxic_score += log_w_given_non_toxic
toxic_score += self.log_class_priors['toxic']
non_toxic_score += self.log_class_priors['non-toxic']
if toxic_score > non_toxic_score:
result.append(1)
else:
result.append(0)
return resultTrain Naive Bayes Classifier for training dataset.
HSD = HateSpeechDetector()
HSD.fit(df_train["tweet"], df_train["label"])
pred = HSD.predict(df_valid["tweet"])
print(metrics.classification_report(df_valid["label"], np.array(pred)))
print(metrics.accuracy_score(df_valid["label"], np.array(pred)))
print(metrics.f1_score(df_valid["label"], np.array(pred)))
print(metrics.confusion_matrix(df_valid["label"], np.array(pred))) precision recall f1-score support
0 0.93 1.00 0.96 5701
1 1.00 0.05 0.09 443
accuracy 0.93 6144
macro avg 0.97 0.52 0.53 6144
weighted avg 0.94 0.93 0.90 6144
0.9314778645833334
0.09462365591397849
[[5701 0]
[ 421 22]]The result got worse. Naive Bayes got lower f1-score (14.7%) on test dataset. Next, I want to try under resampling strategies. We shall know that this is a highly imbalanced datasets (22803 for “0” and 1772 for “1”), so I’m going to adopted resampling technique for dealing with highly imbalanced datasets. It consists of removing samples from the majority class (under-sampling) or adding more examples from the minority class (over-sampling).
# Class count
count_class_0, count_class_1 = df_train.label.value_counts()
# Divide by class
df_class_0 = df_train[df_train['label'] == 0]
df_class_1 = df_train[df_train['label'] == 1]
df_class_0_under = df_class_0.sample(count_class_1)
df_train_under = pd.concat([df_class_0_under, df_class_1], axis=0)
print('Random under-sampling:')
print(df_train_under.label.value_counts())
plt.rcParams["figure.figsize"] = 15, 6
df_train_under.label.value_counts().plot(kind='bar', title='Count (target)');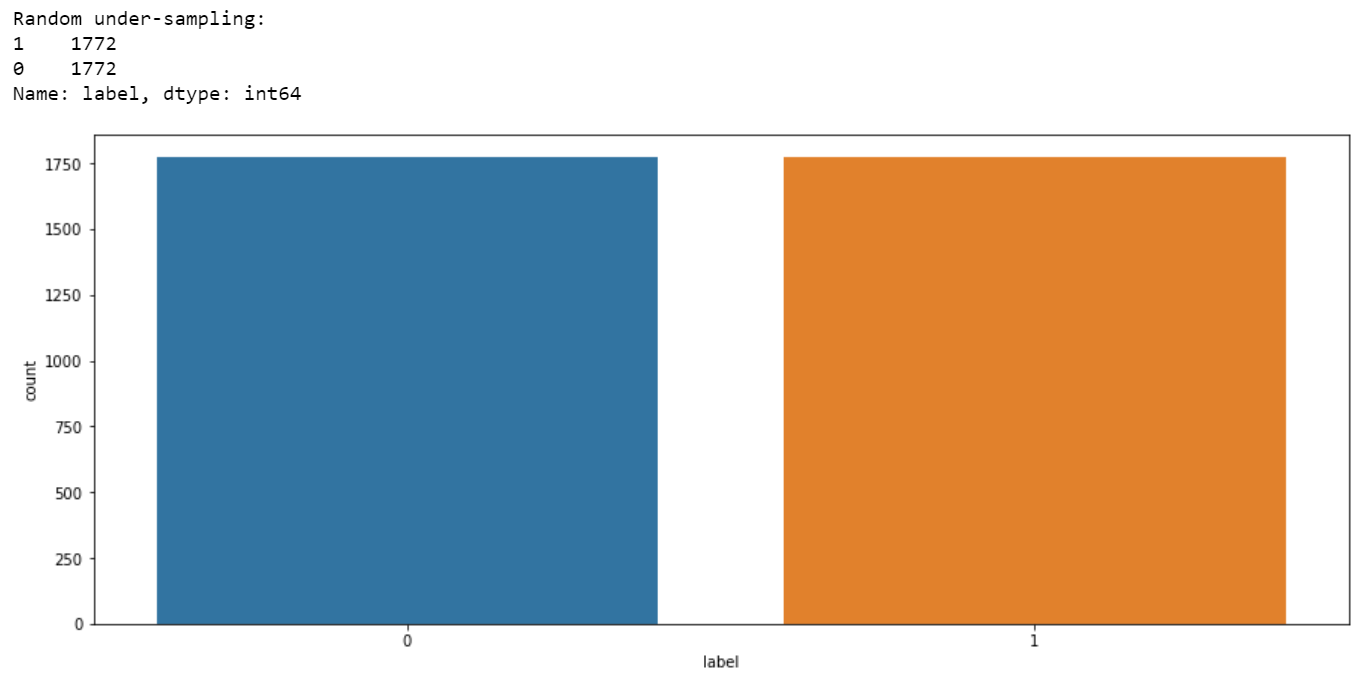
Re-train the Bayes model.
HSD = HateSpeechDetector()
HSD.fit(df_train_under["tweet"], df_train_under["label"])
pred = HSD.predict(df_valid["tweet"])
print(metrics.classification_report(df_valid["label"], np.array(pred)))
print(metrics.accuracy_score(df_valid["label"], np.array(pred)))
print(metrics.f1_score(df_valid["label"], np.array(pred)))
print(metrics.confusion_matrix(df_valid["label"], np.array(pred))) precision recall f1-score support
0 0.99 0.85 0.92 5701
1 0.32 0.87 0.47 443
accuracy 0.86 6144
macro avg 0.65 0.86 0.69 6144
weighted avg 0.94 0.86 0.88 6144
0.8562825520833334
0.46710923355461675
[[4874 827]
[ 56 387]]This time, we got a higher f1-score (46.9%) on test datasets, and it’s even better than the f1-score (29.52%) of BERT.
Therefore, I try to utilise under sampling on BERT again to see if we can increase the f1-score!
train_dataset = TwitterDataset(df_train_under.review.values, df_train_under.label.values, max_len=PARAM.MAX_LENGTH)
valid_dataset = TwitterDataset(df_valid.review.values, df_valid.label.values, max_len=PARAM.MAX_LENGTH)
n_train_steps = int(len(df_train) / 32 * 10)
model = TwitterClassifier(num_train_steps=n_train_steps, num_classes=PARAM.NUM_CLASSES, weight=np.array([1.0, 1.0]))
tb_logger = tez.callbacks.TensorBoardLogger(log_dir=PARAM.TF_LOG)
es = tez.callbacks.EarlyStopping(monitor="valid_loss",
model_path="./models/bert_under.bin",
patience=PARAM.ES_PATIENCE)
model.fit(
train_dataset,
valid_dataset=valid_dataset,
train_bs=PARAM.TRAIN_BATCH_SIZE,
valid_bs=PARAM.VALID_BATCH_SIZE,
device=PARAM.DEVICE,
epochs=PARAM.EPOCH,
callbacks=[tb_logger, es],
n_jobs=PARAM.N_JOB,
fp16=PARAM.FP16,
)
model.save("./models/bert_under.bin")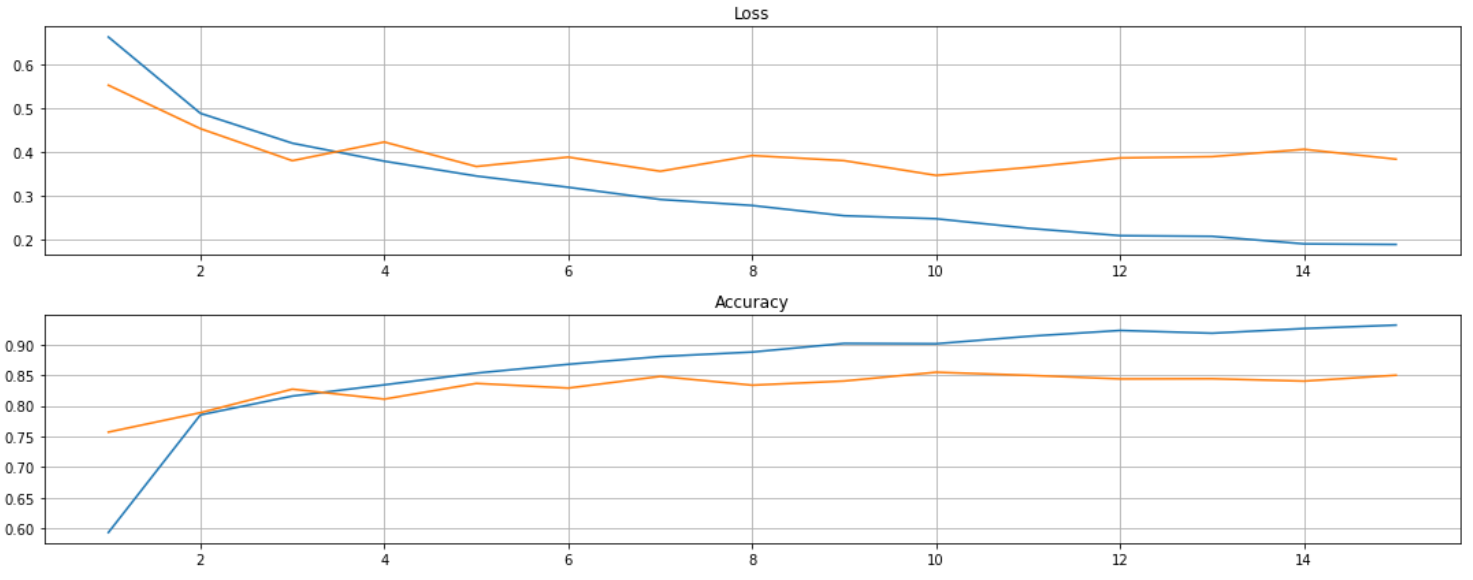
Unfortunately, BERT with under sampling technique get the lowest f1-score (13.1%)…
Data Augmentation
Data augmentation in data analysis are techniques used to increase the amount of data by adding slightly modified copies of already existing data or newly created synthetic data from existing data. It acts as a regularizer and helps reduce overfitting when training a machine learning model.
In this post, I will primarily address data augmentation with regard to the Text Classification and some of these techniques listed below.
- Backtranslation
- Synonym Word Replacement
- Pre-trained Word Embedding based: Word2Vec, , GloVe, FastText, …
- Contexual Word Embedding based: ELMo, BERT, DistilBERT, …
- Lexical based: Wordnet, …
- Generative Models: BERT, XLNet, RoBERTa, BART, T%
- Random Operation:
- Random Insertion
- Random Swapping
- Random Deletion
Naive Bayes with Wordnet Augmentation
I use WordNet, a large linguistic database, to identify relevant synonyms.
import nlpaug.augmenter.char as nac
import nlpaug.augmenter.word as naw
import nlpaug.augmenter.sentence as nas
import nlpaug.flow as nafc
from nlpaug.util import Actionnlpaug helps you with augmenting nlp for your machine learning projects.
def augment_text(df, samples=300):
aug = naw.SynonymAug(aug_src='wordnet')
aug_text = []
# Selecting the minority class samples
df_n = df[df.label==1].reset_index(drop=True)
## Data augmentation loop
for i in tqdm(np.random.randint(0, len(df_n), samples)):
text = df_n.iloc[i]['tweet']
augmented_text = aug.augment(text)
aug_text.append(augmented_text)
return pd.DataFrame({
'tweet': aug_text,
'label': 1})Concatenate with the original dataframe.
df_train_1_aug = augment_text(df_train, samples=20000)
df_train_all_aug = pd.concat([df_train, df_train_1_aug], axis=0)
df_train_all_aug = df_train_all_aug.reset_index(drop=True)
df_train_all_aug["review"] = df_train_all_aug["tweet"].swifter.apply(clean_tweets)
df_train_all_aug["length"] = df_train_all_aug["review"].swifter.apply(len)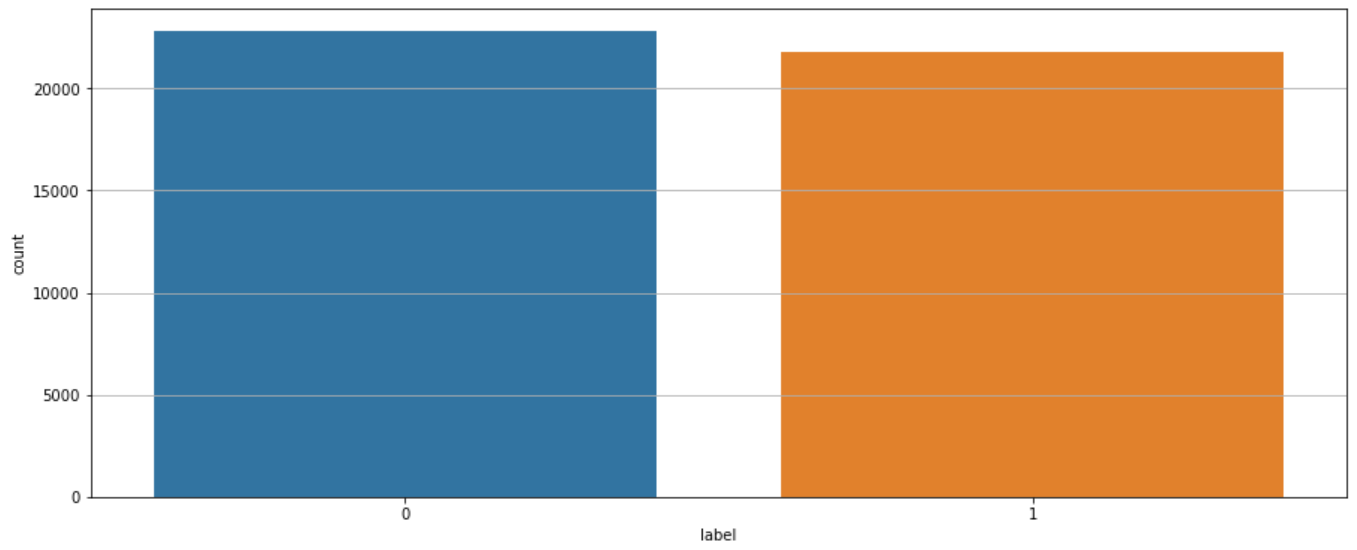
Traing Naive Bayes with text augmentation.
HSD = HateSpeechDetector()
HSD.fit(df_train_all_aug["tweet"], df_train_all_aug["label"])
pred = HSD.predict(df_valid["tweet"])
print(metrics.classification_report(df_valid["label"], np.array(pred)))
print(metrics.accuracy_score(df_valid["label"], np.array(pred)))
print(metrics.f1_score(df_valid["label"], np.array(pred)))
print(metrics.confusion_matrix(df_valid["label"], np.array(pred))) precision recall f1-score support
0 0.98 0.94 0.96 5701
1 0.50 0.80 0.61 443
accuracy 0.93 6144
macro avg 0.74 0.87 0.79 6144
weighted avg 0.95 0.93 0.93 6144
0.9269205729166666
0.6112554112554112
[[5342 359]
[ 90 353]]It got a f1-score of 63.1% on test dataset! Seems pretty well! In this case, I was wondering, what if I do the same text augmentation operation on validation data? Will it increase the accuracy and f1-score? Let’s see!
df_valid_1_aug = augment_text(df_valid, samples=5000)
df_valid_all_aug = pd.concat([df_valid, df_valid_1_aug], axis=0)
df_valid_all_aug = df_valid_all_aug.reset_index(drop=True)
df_valid_all_aug["review"] = df_valid_all_aug["tweet"].swifter.apply(clean_tweets)
df_valid_all_aug["length"] = df_valid_all_aug["review"].swifter.apply(len)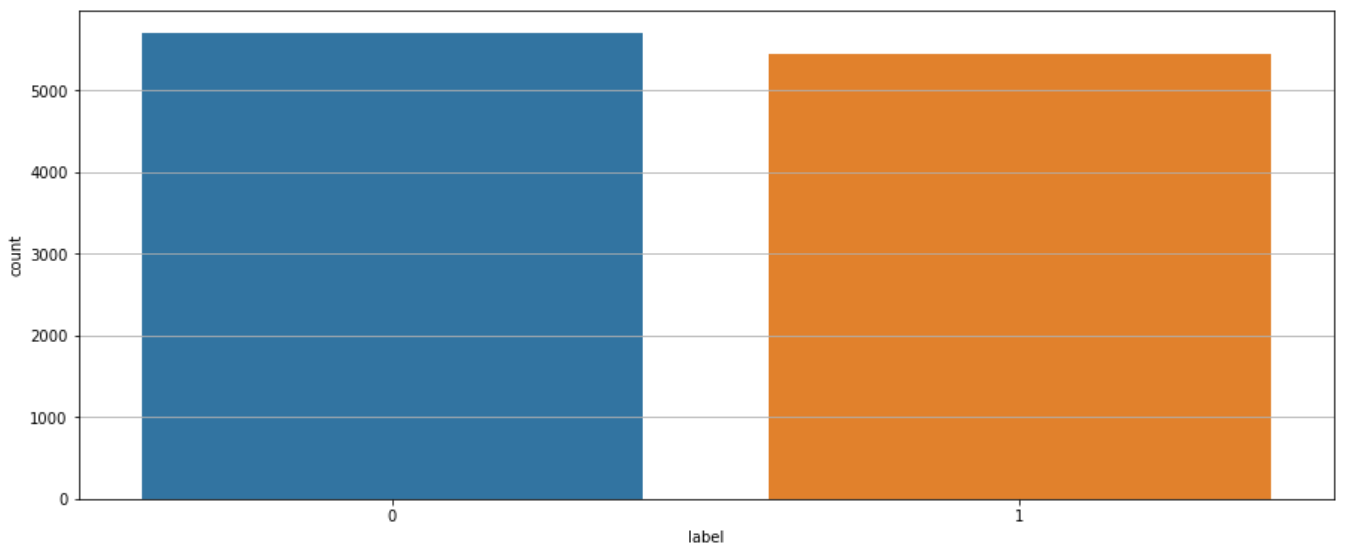
HSD = HateSpeechDetector()
HSD.fit(df_train_all_aug["tweet"], df_train_all_aug["label"])
pred = HSD.predict(df_valid_all_aug["tweet"])
print(metrics.classification_report(df_valid_all_aug["label"], np.array(pred)))
print(metrics.accuracy_score(df_valid_all_aug["label"], np.array(pred)))
print(metrics.f1_score(df_valid_all_aug["label"], np.array(pred)))
print(metrics.confusion_matrix(df_valid_all_aug["label"], np.array(pred))) precision recall f1-score support
0 0.93 0.94 0.94 5701
1 0.93 0.93 0.93 5443
accuracy 0.93 11144
macro avg 0.93 0.93 0.93 11144
weighted avg 0.93 0.93 0.93 11144
0.9339554917444365
0.9322782480677219
[[5342 359]
[ 377 5066]]It got a f1-score of 63.6% on test dataset! It’s slightly higher than only operating augmentation on training dataset.
Naive Bayes with BERT Augmentation
def augment_text_using_bert(df, samples=300):
aug = naw.ContextualWordEmbsAug(model_path='bert-base-uncased', action="substitute")
aug_text = []
# Selecting the minority class samples
df_n = df[df.label==1].reset_index(drop=True)
## Data augmentation loop
for i in tqdm(np.random.randint(0, len(df_n), samples)):
text = df_n.iloc[i]['tweet']
augmented_text = aug.augment(text)
aug_text.append(augmented_text)
return pd.DataFrame({
'tweet': aug_text,
'label': 1})Basically, the code is the same as the previous. I listed the result (on test dataset) in one table.
| Model | Augmentation | F1-score |
|---|---|---|
| Naive Bayes | Wordnet (Train) | 🥈 0.6307 |
| Naive Bayes | Wordnet (Train+Valid) | 🥇 0.6356 |
| Naive Bayes | BERT (Train) | 0.5136 |
| Naive Bayes | BERT (Train+Valid) | 🥉 0.5200 |
Next, I investigate the wordnet augmentation on training datatset for BERT model. This results in a lower f1-score of 35.2% on test dataset.
Conclusion
In this report, I proposed several solutions to the detection of hate speech and offensive language on Twitter through machine learning (Naive Bayes) and deep learning (BERT). Most of the time, BERT performed worse than Naive Bayes. In the future, if I have spare time, I may try ensemble methods to see whether it can increase the f1-score significantly! See you next time!
References
- https://github.com/abhishekkrthakur/tez
- https://www.kaggle.com/renatobmlr/pytorch-imbalanced-classes
- https://github.com/makcedward/nlpaug/blob/master/example/textual_augmenter.ipynb
- https://arxiv.org/pdf/1904.00962.pdf
- https://pythonmachinelearning.pro/text-classification-tutorial-with-naive-bayes/
- https://www.kaggle.com/getting-started/14998
- https://neptune.ai/blog/data-augmentation-nlp
- https://saurabhk30.medium.com/5-data-augmentation-techniques-for-text-classification-d14f6d8bd6aa

