When I was doing my dissertation project, I found out that the performance of model wasn’t quite well. I believe it’s because the domain of pre-trained GoogleNews-vectors-negative300 is different from the the dataset of mine. Hence, I decide to pre-train a word2vec model by myself. In this article, I’ll use a library called “Koan” released by Bloomberg LP. They build CBOW model using C++, which is more efficiently compared to word2vec and gensim libraries. If you are a Windows user, and you don’t have a Linux system in your computer, please read this [article] I wrote before to set up your WSL.
Introduction
The reason we care about language is that, because of language, we are able to turn invisible ideas into visible actions. However, language is ambiguous at all levels: lexical, phrasal, semantic. To address this, we need to build a language model, which can convert text into vectors. The most common techniques are Bag of Words (One-Hot Encoding, TF-IDF), Distributional Word Embedding (Word2Vec, GloVe, FastText), and Contextualised Word Embedding (ELMo, BERT). In this article, I’m gonna implement Word2Vec to generate pre-trained vectors.
Word2Vec
Word2Vec is a statistical-based method to obtain word vectors, and it is proposed by Tomas Mikolov et al. [4] of Google in 2013. Word2Vec is available in two flavors, the CBoW model and the Skip-Gram model, which is based on neural networks which can map words to low dimensional space. CBoW model predicts the current word by context, and Skip-Gram model predicts context by current word.
Text Pre-processing
First, you need to read in your csv file containing texts.
df = pd.read_csv(r"./20061020_20131126_bloomberg_news.csv")
df["title"] = df["title"].apply(str)
df["paragraph"] = df["paragraph"].apply(str)
df.sample(3)| title | timestamp | paragraph | |
|---|---|---|---|
| 6493 | Coronavirus: Malaysia’s Economy Shows Doing th… | 2020/8/23 | Strict lockdowns, accommodative central banks,… |
| 1833 | Lower Rates: Trump and the Markets Picked Thei… | 2019/8/7 | Collapsing bond yields aren’t exactly a sign … |
| 4376 | Crypto Brokerage Tagomi Gets $12 Million in Se… | 2019/3/4 | Tagomi Holdings Inc., a digital asset brokerag… |
Second, put them into a list.
documents = []
documents.extend(df.loc[:, ["title", "paragraph"]].values.flatten().tolist())Third, do some text cleaning work.
def regex(text):
text = re.sub(r"([^a-zA-Z0-9\.\?\,\!\%\']+)", " ", text)
text = re.sub(r"(?<=\d),(?=\d)+", "", text)
text = re.sub(r"\,", " , ", text)
text = re.sub(r"\?", " ? ", text)
text = re.sub(r"\!", " ! ", text)
text = re.sub(r"\.", " . ", text)
text = re.sub(r" ", " ", text)
text = text.strip()
return text
docs = [regex(doc) for doc in documents]
docs_cased = [regex(doc.lower()) for doc in documents]Tokenisation
You’ll need to prepare your corpus as a single text file with all words separated by one or more spaces or tabs.
def progressbar(iter, prefix="", size=50, file=sys.stdout):
count = len(iter)
def show(t):
x = int(size*t/count)
# file.write("%s[%s%s] %i/%i\r" % (prefix, "#"*x, "."*(size-x), int(100*t/count), 100))
file.write("{}[{}{}] {}%\r".format(prefix, "█"*x, "."*(size-x), int(100*t/count)))
file.flush()
show(0)
for i, item in enumerate(iter):
yield item
show(i+1)
file.write("\n")
file.flush()
class Tokenizer(object):
def __init__(self,
char_level=False,
num_tokens=None,
pad_token='<PAD>',
oov_token='<UNK>',
token_to_index=None
):
self.char_level = char_level
self.separator = '' if self.char_level else ' '
# <PAD> + <UNK> tokens
if num_tokens: num_tokens -= 2
self.num_tokens = num_tokens
self.oov_token = oov_token
if not token_to_index:
token_to_index = {'<PAD>': 0, '<UNK>': 1}
self.token_to_index = token_to_index
self.index_to_token = {v: k for k, v in self.token_to_index.items()}
def __len__(self):
return len(self.token_to_index)
def __str__(self):
return f"<Tokenizer(num_tokens={len(self)})>"
def fit_on_texts(self, texts):
if self.char_level:
all_tokens = [token for text in texts for token in text]
if not self.char_level:
all_tokens = [token for text in texts for token in text.split(' ')]
counts = Counter(all_tokens).most_common(self.num_tokens)
self.min_token_freq = counts[-1][1]
for token, count in progressbar(counts, prefix="VOCAB"):
index = len(self)
self.token_to_index[token] = index
self.index_to_token[index] = token
return self
def texts_to_sequences(self, texts):
sequences = []
for text in progressbar(texts, prefix="TEXT2SEQ"):
if not self.char_level:
text = text.split(' ')
sequence = []
for token in text:
sequence.append(self.token_to_index.get(
token, self.token_to_index[self.oov_token]))
sequences.append(sequence)
return sequences
def sequences_to_texts(self, sequences):
texts = []
for sequence in progressbar(sequences, prefix="SEQ2TEXT"):
text = []
for index in sequence:
text.append(self.index_to_token.get(index, self.oov_token))
texts.append(self.separator.join([token for token in text]))
return texts
def save(self, fp):
with open(fp, 'w') as fp:
contents = {
'char_level': self.char_level,
'oov_token': self.oov_token,
'token_to_index': self.token_to_index
}
json.dump(contents, fp, indent=4, sort_keys=False)
@classmethod
def load(cls, fp):
with open(fp, 'r') as fp:
kwargs = json.load(fp=fp)
return cls(**kwargs)tokeniser = Tokenizer(char_level=False, num_tokens=1000000)
tokeniser.fit_on_texts(docs_cased[:])
sequences = tokeniser.texts_to_sequences(docs_cased[:])
texts = tokeniser.sequences_to_texts(sequences)
print(sequences[0:5])
print("="*50)
print(texts[0:5])[[21789, 358380, 4, 37272, 4, 61540, 358381, 5009, 1964, 5, 2902, 37914], [21789, 4, 37272, 4, 61540, 9, 1133, 34, 1299, 3, 122, 577, 10, 123, 6313, 1253, 294, 8, 547, 11, 25, 304, 2], [7233, 80031, 1117, 546, 47, 9039, 6, 39, 2225, 7, 29623], [328, 19, 1338, 16712, 6, 126, 179, 2, 305, 241, 14, 11689, 606, 2848, 3368, 4, 3, 1166, 1794, 19, 552, 4, 32651, 34, 259, 4, 2902, 577, 10, 2514, 1352, 8, 252, 2, 9, 596, 13, 18410, 4, 850, 606, 3, 7233, 80031, 2], [304, 6076, 3389, 19, 6, 4488, 90, 1037, 488]]
==================================================
['ethereum xet , xrp , litecoin xlc cryptocurrency alternative to bitcoin btc', 'ethereum , xrp , litecoin and others are giving the world ? s most famous digital currency a run for its money .', 'crypto opportunists create 500 more coins in new phase of mania', 'risk is running rampant in financial markets . stocks trade at dot come era valuations , the ipo pipeline is full , spacs are back , bitcoin ? s headed toward a record . and right on cue , here come the crypto opportunists .', 'money stuff exxon is in trouble over climate change']After tokenised our corpus, save it to a news.tokens file.
with open('./news.tokens', 'w') as f:
for item in texts:
f.write("%s\n" % item)Training Process
Word2vec is a two-layer neural net that processes text by “vectorizing” words. Its input is a text corpus and its output is a set of vectors: feature vectors that represent words in that corpus.
CBOW
Move your news.tokens file to WSL folder. In my case, it is at C:\Users\yangwang\AppData\Local\Packages\CanonicalGroupLimited.Ubuntu18.04onWindows_79rhkp1fndgsc\LocalState\rootfs\home\yang\.
Next, open your mobaxterm and execute the following code.
sudo ./build/koan -V 1000000 \
--epochs 10 \
--dim 300 \
--negatives 5 \
--context-size 5 \
-l 0.075 \
--threads 16 \
--cbow true \
--min-count 2 \
--file ./news.tokensLearned embeddings will be saved to embeddings_${CURRENT_TIMESTAMP}.txt in the present working directory.
Skip-Gram
Similarly, you can get the pre-trained vectors by Skip-Gram, just set cbow to false.
sudo ./build/koan -V 1000000 \
--epochs 10 \
--dim 300 \
--negatives 5 \
--context-size 5 \
-l 0.075 \
--threads 16 \
--cbow false \
--min-count 2 \
--file ./news.tokensConvert GloVe Format to Word2Vec Format
Move your pre-trained vectors back to your Windows folder, and change your file name to news-cbow-negative300.txt (or news-skipgram-negative300.txt, depend on how you trained it). We then convert GloVe vectors format into the word2vec format.
from gensim.models import KeyedVectors
from gensim.scripts.glove2word2vec import glove2word2vec
_ = glove2word2vec("./news-cbow-negative300.txt", "./news-word2vec-cbow-negative300.txt")
wv_from_text = KeyedVectors.load_word2vec_format("./news-word2vec-cbow-negative300.txt", binary=False)Notes
GloVe format (a real example can be found on the Stanford site)
word1 0.123 0.134 0.532 0.152
word2 0.934 0.412 0.532 0.159
word3 0.334 0.241 0.324 0.188
...
word9 0.334 0.241 0.324 0.188Word2Vec format (a real example can be found in the old w2v repository).
9 4
word1 0.123 0.134 0.532 0.152
word2 0.934 0.412 0.532 0.159
word3 0.334 0.241 0.324 0.188
...
word9 0.334 0.241 0.324 0.188Voilà! You have successfully got a pre-trained word embedding!
wv_from_text.similar_by_word("bitcoin")[('cryptocurrency', 0.7397603392601013),
('cryptocurrencies', 0.7099655866622925),
('crypto', 0.6509920358657837),
('xrp', 0.5511361360549927),
('ethereum', 0.547865629196167),
('monero', 0.5345401167869568),
("bitcoin's", 0.5305401086807251),
('bitcoins', 0.5253546237945557),
('gold', 0.5229815244674683),
('blockchain', 0.508536159992218)]Train GloVe on WSL
GloVe (Global Vectors for Word Representation) is an alternate method to create word embeddings. It is based on matrix factorization techniques on the word-context matrix.
Download GloVe
Download GloVe library from Standford’s GitHub
git clone https://github.com/stanfordnlp/glove
cd glove && make
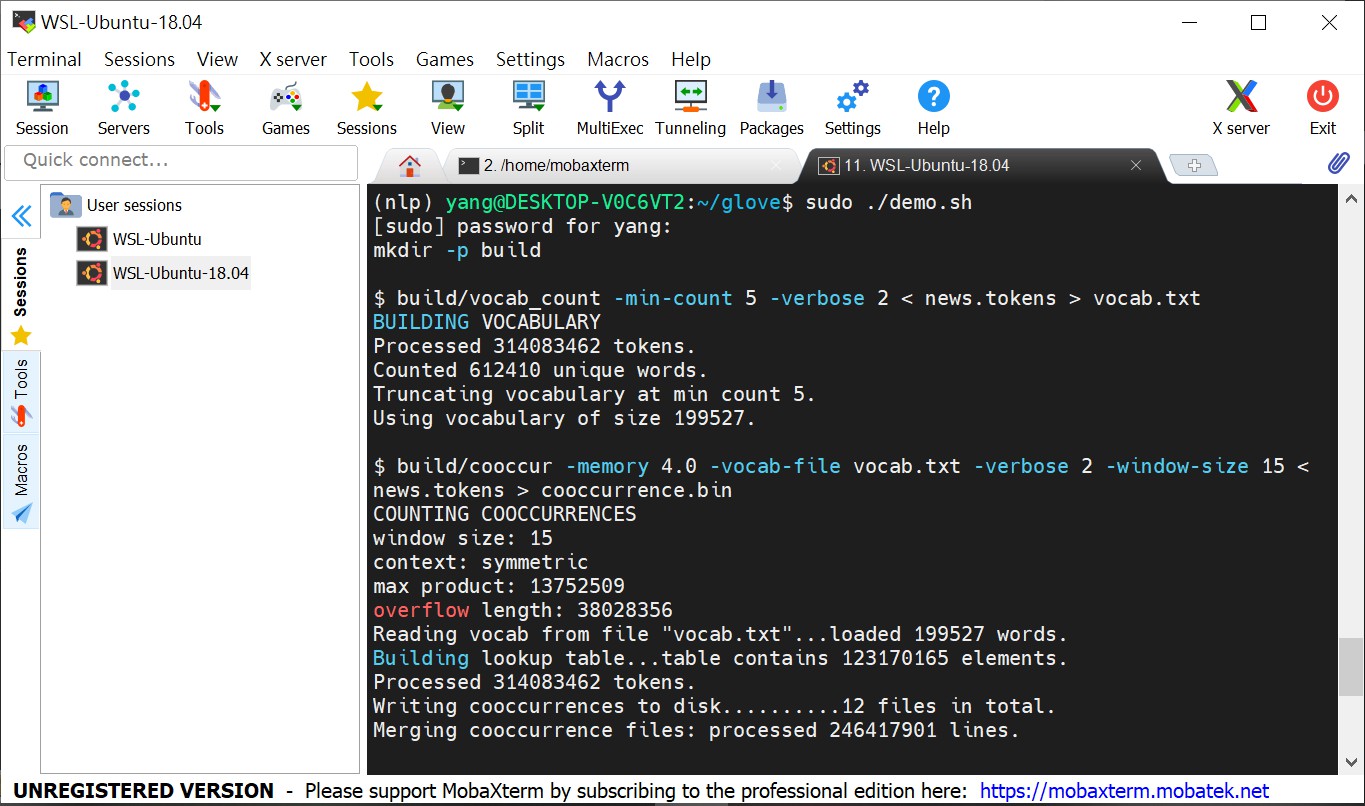
./demo.shTraining Process
This is how you run the model:
git clone http://github.com/stanfordnlp/glove
cd glove && makeTo train it on your own corpus, you just have to make changes to one file, that is demo.sh.
Remove the script from if to fi after make. Replace the CORPUS name with your file name, in our case, news.tokens There is another if loop at the end of file demo.sh.
if [ "$CORPUS" = 'text8' ]; thenReplace text8 with news.tokens.
Run the demo.sh once the changes are made.
$ ./demo.shDon’t forget to keep your corpus file directly inside the Glove folder. Make sure your corpus file is in the correct format.You’ll need to prepare your corpus as a single text file with all words separated by one or more spaces or tabs. If your corpus has multiple documents, the documents (only) should be separated by new line characters.
Sometimes, you have trouble with running ./demo.sh. When you use ./demo.sh, you’ll get sudo: demo.sh: command not found.
Here’s a summary of how to troubleshoot the Permission Denied error in our case.
$ ls -l demo.sh # Check file permissions of demo.sh
---------- 1 yang yang 0 2039-10-21 14:47 foo.sh
^^^
^^^ | ^^^ ^^^^ ^^^^
| | | | |
Owner| World | |
| | Name of
Group | Group
Name of
OwnerOwner has no read and write access rw and the - indicates that the executable permission is missing. The chmod command fixes that. (Group and other only have read permission set on the file, they cannot write to it or execute it).
chmod +x demo.sh
chmod +r demo.sh
chmod +w demo.sh
ls -l demo.shdemo.sh is now executable as far as Linux is concerned.
Convert GloVe Format to Word2Vec Format
_ = glove2word2vec("./news-glove-vectors300.txt", "./news-glove-w2vformat-vectors300.txt")
wv_glove = KeyedVectors.load_word2vec_format("./news-glove-w2vformat-vectors300.txt", binary=False)Test it on ‘bitcoin’ token.
wv_glove.similar_by_word("bitcoin")[('cryptocurrency', 0.7422985434532166),
('cryptocurrencies', 0.6949392557144165),
('crypto', 0.6679537296295166),
('blockchain', 0.5640972852706909),
('bitcoins', 0.4695727825164795),
('ethereum', 0.4689256548881531),
('ether', 0.4526808261871338),
('virtual', 0.43389463424682617),
('tokens', 0.42009514570236206),
('coins', 0.418658971786499)]Train FastText on WSL
FastText is a library for efficient learning of word representations and sentence classification. FastText builds on modern Mac OS and Linux distributions. Since it uses C++11 features, it requires a compiler with good C++11 support.
Download FastText
Install FastText.
wget https://github.com/facebookresearch/fastText/archive/v0.9.2.zip
unzip v0.9.2.zipAnd move to the FastText directory and build it.
cd fastText-0.9.2
make
pip install .Training Process
Training word vectors using skipgram:
sudo ./fasttext skipgram -input news.tokens -output news-fasttext-skipgram-vectors300 -minn 3 -maxn 6 -dim 300Training word vectors using cbow:
sdudo ./fasttext cbow -input news.tokens -output news-fasttext-cbow-vectors300 -minn 3 -maxn 6 -dim 300where news.tokens is the training file containing UTF-8 encoded text we used before. By default the word vectors will take into account character n-grams from 3 to 6 characters. At the end of optimization the program will save two files: skipgram-model.bin and cbow-model.vec. model.vec is a text file containing the word vectors, one per line. model.bin is a binary file containing the parameters of the model along with the dictionary and all hyper parameters. The binary file can be used later to compute word vectors or to restart the optimization.
Instead of training through command line, you can also train it using Python.
import fasttext
model = fasttext.train_unsupervised('news.tokens',
"cbow",
minn=3,
maxn=6,
dim=300,
epoch=5,
lr=0.05,
thread=12)
model.save_model("news-fasttext-cbow-vectors300.bin")
wv_fasttext_cbow = fasttext.load_model("news-fasttext-cbow-vectors300.bin")Depending on the quantity of data you have, you may want to change the parameters of the training. The epoch parameter controls how many times the model will loop over your data. By default, we loop over the dataset 5 times. If you dataset is extremely massive, you may want to loop over it less often. Another important parameter is the learning rate -lr. The higher the learning rate is, the faster the model converge to a solution but at the risk of overfitting to the dataset. The default value is 0.05 which is a good compromise. If you want to play with it we suggest to stay in the range of [0.01, 1]. Finally , fastText is multi-threaded and uses 12 threads by default. If you have less CPU cores (say 4), you can easily set the number of threads using the thread flag.
Printing Word Vectors
wv_fasttext_cbow.get_word_vector("bitcoin")array([-4.72412445e-02, 2.85789132e-01, 3.42660360e-02, 2.09649026e-01,
-4.54065323e-01, -1.91382036e-01, -5.00535131e-01, 1.86818153e-01,
3.03504705e-01, -1.97448403e-01, 1.50050864e-01, 6.53051957e-02,
-7.71196038e-02, -8.81627798e-02, 3.74232829e-02, 1.92417011e-01,
3.55105817e-01, 3.28541487e-01, -3.44138265e-01, -4.90421832e-01,
-2.13972241e-01, 1.74339145e-01, -3.67868505e-02, 1.09374836e-01,
3.75284493e-01, 1.03113867e-01, -1.45857438e-01, -3.04340214e-01,
-2.54121244e-01, 1.69611394e-01, -2.09063217e-01, 2.09711909e-01,
-1.41518816e-01, 1.25664864e-02, 3.95129383e-01, -1.39495045e-01,
8.94690026e-03, 4.83614445e-01, 7.68003613e-02, -1.72020838e-01,
2.65787989e-01, 6.64022043e-02, 1.34228259e-01, 4.24850464e-01,
5.29484272e-01, 7.14946613e-02, -1.55057460e-01, 6.64764345e-02,
-1.79950804e-01, 2.07342580e-02, -5.48851252e-01, 2.00532869e-01,
2.39266697e-02, -3.15076023e-01, 1.58537552e-01, -1.75947800e-01,
-4.23456818e-01, 2.27220535e-01, -1.18757211e-01, -1.85626462e-01,
2.09006771e-01, -1.08534403e-01, 2.79801786e-01, -1.84326231e-01,
3.45385611e-01, 2.19469175e-01, -1.65827513e-01, -9.27144065e-02,
-9.44910273e-02, 4.01960224e-01, 2.21235991e-01, -2.24734709e-01,
5.92879727e-02, 3.68174642e-01, -1.62111774e-01, -3.60321164e-01,
-3.73723418e-01, -2.35717162e-01, -4.61407304e-01, -1.32908091e-01,
6.76851049e-02, 2.14217320e-01, -4.72074896e-01, 1.62981063e-01,
3.71879905e-01, 1.01424217e-01, -2.97889352e-01, -3.91066521e-01,
-2.46688813e-01, 5.42590201e-01, -1.35109276e-01, 3.26993912e-01,
2.32391551e-01, 2.00287759e-01, -1.49581164e-01, -2.75721133e-01,
4.79313314e-01, 2.26864532e-01, -1.83264613e-02, 1.18657842e-01,
1.28447264e-01, -3.34220439e-01, 2.69317508e-01, -2.59843171e-01,
3.10199022e-01, 2.16098920e-01, -1.86288506e-01, 5.94185330e-02,
-4.23078507e-01, 5.34226038e-02, 2.08673358e-01, -1.05236337e-01,
3.77959639e-01, -1.97113946e-01, 3.33479345e-01, 3.94979984e-01,
1.35598034e-01, 7.51101971e-03, 2.95481265e-01, -2.15200692e-01,
2.40353987e-01, 3.65436196e-01, -1.55092150e-01, 1.55085281e-01,
-4.16599452e-01, -3.74957502e-01, -8.32035206e-03, -7.39385858e-02,
2.17583347e-02, -3.48901063e-01, -9.27907787e-03, 1.24386065e-01,
7.21558109e-02, -5.65859616e-01, 2.39448603e-02, -6.12365842e-01,
-3.45480561e-01, 6.63597524e-01, -5.31071126e-01, -3.11197668e-01,
-2.66234726e-01, 4.01567996e-01, 7.12649003e-02, 2.27668926e-01,
3.60199302e-01, 1.40796080e-01, -1.30780600e-02, -4.35646117e-01,
-3.15058351e-01, 1.79761440e-01, -7.38127008e-02, -1.57344565e-01,
-1.30275175e-01, -2.29776427e-01, -3.11963826e-01, 2.51461089e-01,
-7.77154416e-02, -1.93161428e-01, -1.22963764e-01, 1.19474560e-01,
-1.70210376e-02, -6.77634845e-04, 7.12327287e-03, -2.26126343e-01,
2.12814316e-01, 1.10432744e-01, -3.75197530e-01, -2.51778066e-01,
2.61254579e-01, -1.91191047e-01, 1.73024654e-01, -1.69590712e-01,
1.13725312e-01, -4.02675480e-01, -7.49008298e-01, -4.75077957e-01,
4.30675596e-03, -5.70537090e-01, -3.68678004e-01, -1.18338585e-01,
1.02712013e-01, 1.67967491e-02, 5.66727901e-03, 5.40452838e-01,
4.11487877e-01, 6.39163136e-01, 4.11166042e-01, -2.50596225e-01,
-1.04347736e-01, -2.55890310e-01, 1.25067562e-01, 3.32301527e-01,
1.40600502e-01, -2.42391825e-01, -1.40091211e-01, -2.05069736e-01,
-5.73189482e-02, 2.14646116e-01, -2.63260067e-01, 2.00784519e-01,
2.35700160e-01, 3.53334904e-01, 5.38006604e-01, 1.59950554e-01,
1.52627319e-01, -2.47434601e-01, -6.53754920e-02, -1.69809297e-01,
-2.81990021e-01, -4.69022483e-01, -1.67136639e-01, 2.62764134e-02,
-1.31334037e-01, 5.59901476e-01, -1.58817634e-01, -3.86552542e-01,
-3.78590643e-01, 1.53091252e-01, 1.59801438e-01, 3.00560832e-01,
9.51611772e-02, -1.25739768e-01, -2.82772869e-01, -2.11738721e-01,
-1.44721761e-01, 3.01432371e-01, -2.95276958e-02, -4.21232760e-01,
1.95821151e-01, -1.03478849e-01, 3.75818871e-02, 7.30549470e-02,
-1.24263890e-01, 4.21253517e-02, 5.34670353e-02, -6.04710579e-02,
4.18751776e-01, -1.89714432e-01, 7.75871202e-02, 2.64797509e-01,
6.84403598e-01, -2.88427889e-01, 2.65219778e-01, -9.75028351e-02,
-2.16612965e-01, -1.84845805e-01, 3.57705653e-01, 1.84521660e-01,
-2.25650191e-01, -2.41775334e-01, 6.35201484e-02, 1.05721205e-01,
-2.76269794e-01, 7.44905397e-02, -4.05652225e-01, -3.25192034e-01,
1.33607000e-01, -2.70021617e-01, -5.09377658e-01, 8.15921091e-03,
1.39862090e-01, 2.68142492e-01, 3.83002162e-01, 1.91613629e-01,
2.66971558e-01, -2.08550826e-01, -1.84474185e-01, 2.28107542e-01,
-1.41805783e-01, -3.34146500e-01, 5.33484481e-02, 1.27584279e-01,
8.07003453e-02, 1.00570947e-01, -4.74314131e-02, 2.64507622e-01,
5.04497468e-01, 8.56446847e-02, 4.17862684e-01, 1.42475590e-01,
-1.79341078e-01, -2.17798918e-01, 8.03667828e-02, -1.44884512e-01,
-2.44018864e-02, -7.17387274e-02, 8.83749798e-02, 1.36670202e-01,
-1.49312671e-02, -4.16279852e-01, 1.23666152e-01, 4.03715611e-01,
3.15533012e-01, 2.58996665e-01, -2.77972668e-01, 1.68511316e-01,
1.92251951e-01, 1.12253219e-01, -4.47139591e-01, 2.39150673e-01],
dtype=float32)Nearest neighbor queries
A simple way to check the quality of a word vector is to look at its nearest neighbors. This give an intuition of the type of semantic information the vectors are able to capture.
wv_fasttext_cbow.get_nearest_neighbors('bitcoin')[(0.8654916286468506, 'cryptocurrency'),
(0.8515545725822449, 'bitcoins'),
(0.8421329855918884, 'bitcointalk'),
(0.8405554890632629, 'cryptocurrencies'),
(0.8251032829284668, 'tcoin'),
(0.8214054703712463, 'bitcoiners'),
(0.8096168637275696, "cryptocurrency's"),
(0.8051686882972717, 'crypto'),
(0.8023344278335571, "bitcoin's"),
(0.7836618423461914, 'altcoin')]Even if the word is misspell, the fasttext model can also get the correct embedding.
wv_fasttext_cbow.get_nearest_neighbors('bittcoin')[(0.8647432923316956, 'tcoin'),
(0.8488795161247253, 'bitcoin'),
(0.8280304074287415, 'altcoin'),
(0.8253008127212524, 'virtcoin'),
(0.7866906523704529, 'basecoin'),
(0.7821307182312012, 'gatecoin'),
(0.7780086994171143, 'litecoin'),
(0.7758980989456177, 'estcoin'),
(0.7743834853172302, 'cryptocurrency'),
(0.7679258584976196, 'filecoin')]To sum up, FastText utilises subword information, while Word2Vec and GloVe don’t. The result does not make much sense when we take uncommon word like ‘weltschmerz’, most of these words are unrelated or not in the vocabulary. On the other hand, using subword information captures different variation around the word.
Conclusion
You can now perform various syntactic/semantic NLP word tasks with the trained vectors! Cheers!

