Introduction
Text is a very important unstructured data, and how to represent text data has been an important research direction in the field of machine learning. In this article, I will only discuss the very basic methods, such as Bag of Words, TF-IDF (Term Frequency Inverse Document Frequency), Topic Model, and Word Embedding.
Bag of Words & N-gram Model
The most basic text representation model is the bag of words (BoW) model. As the name implies, each text is viewed as a bag of words and ignoring the order in which each word appears. Specifically, the whole text is sliced and diced in terms of words. Each article can then be represented as a long vector, each dimension in the vector represents a word, and the corresponding weight of the dimension reflects the importance of the word in the original article. Most commonly used is TF-IDF (Term Frequency Inverse Document Frequency), it can be denoted as
where
where
It is sometimes not a good practice to classify articles at word level, for example, the English “new york”, if the words “new” and “york” are separated, the meaning is very different from the meaning of the two words when they appear consecutively. Usually, it is possible to put consecutive occurrence of
Topic Model
In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents. There are some famous algorithms, such as Latent Semantic Analysis and Latent Dirichlet Allocation, I will discuss those stuff in the future. Just bear in mind, topic modeling is a frequently used text-mining tool for discovery of hidden semantic structures in a text body.
Word Embedding
Word embedding is a general term for some kind of models that vectorise words, and the core idea behind this is that each word is mapped into a dense vector on a low-dimensional space (usually 50 to 300 dimensions) as a dense vector. Each of the K-dimensional space dimension can also be considered as an implicit topic, but not as intuitive as the topic in the topic model.
Word2Vec, proposed by Google in 2013, is one of the most commonly used word embedding models today. Word2Vec actually is a shallow neural network model which has two network structures, CBOW (Continues Bag of Words) and Skip-gram. CBOW is trained to predict a single word from a fixed window size of context words, whereas Skip-gram does the opposite, and tries to predict several context words from a single input word.
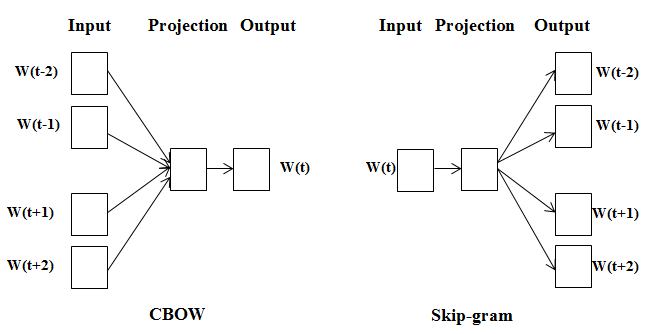
where w(t) is the word of current interest, w(t-2), w(t-1), w(t+1), w(t+2) are the contextual occurrences of the words. Here the sliding window size is set to 2 for both front and back. Both CBOW and Skip-gram can be represented as a neural network consisting of an input layer, a projection layer, and an output layer. Each word in the input layer is represented by one-hot encoding, i.e., all words are represented as an N-dimensional vector, where N is the total number of words in the vocabulary. In the vector, each word has its corresponding dimension set to 1 and the rest values are set to 0. In the projection layer (also known as the hidden layer), the values of the K hidden units can be obtained from the N-dimensional input vector and the N × K dimensional weight matrix connecting the input and the hidden units. In CBOW, it is also necessary to sum the computed hidden units for each input word. Similarly, the value of the output layer vector can be obtained from the projection layer vector (K dimensions), and the K × N dimensional weight matrix connecting the projection layer and the output layer. The output layer is also an N-dimensional vector, and each dimension corresponds to a word in the vocabulary. Finally, applying the Softmax activation function to the output layer vector, it can calculate the probability of each single word’s generation probability. The Softmax activation function is defined as
Learning the weights can be implemented using a backpropagation algorithm, where each weight is updated in one small step along the direction of the better gradient at each iteration. However, due to the presence of a normalization term in the Softmax activation function, the derived iterative formula needs to iterate over all words in the vocabulary. This makes the process of each iteration very slow, which leads to the Hierarchical Softmax and Negative Sampling.
Topic Model VS Word Embedding
Topic model is a generative model based on a probabilistic graphical model whose likelihood function can be written in the form of a number of multiplications of conditional probabilities, including the latent variables (i.e., topics) to be speculated on. While the word embedding model is generally expressed in the form of a neural network, the likelihood function is defined over the output of the network, and the weights of the network need to be learned to obtain a dense vector representation of the words.
Conclusion
There you have the some major approaches to representing text data for NLP tasks. We are now ready to have a look at some practical NLP tasks next time around.

