Introduction
The goal of this article is to create an algorithm that can understand simple spoken commands using the Speech Commands Dataset. We can improve product effectiveness and accessibility by improving the recognition accuracy of open-source voice interface tools.
Speech Commands Data Set v0.01
This is a collection of one-second .wav audio files, each of which contains a single spoken English word. These are words from a small list of commands that are spoken by a variety of people. The audio files are categorised by the words they contain, and this data set is intended to aid in the training of simple machine learning models. The dataset can be downloaded at here.
Read the Data
As usual, first import the packages.
import os
import math
import librosa
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from tqdm import tqdm
from python_speech_features import mfcc
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_scoreTake a look at one of the sample wave files.
train_audio_path = "./data/train/audio/"
filename = 'yes/0a7c2a8d_nohash_0.wav'
sample_rate, samples = wavfile.read(str(train_audio_path) + filename)
fig = plt.figure(figsize=(15, 6))
ax1 = fig.add_subplot(2, 1, 1)
ax1.set_title('Raw wave of ' + f'{str(train_audio_path) + filename}')
ax1.set_xlabel('time')
ax1.set_ylabel('Amplitude')
ax1.plot(np.linspace(0, sample_rate/len(samples), sample_rate), samples)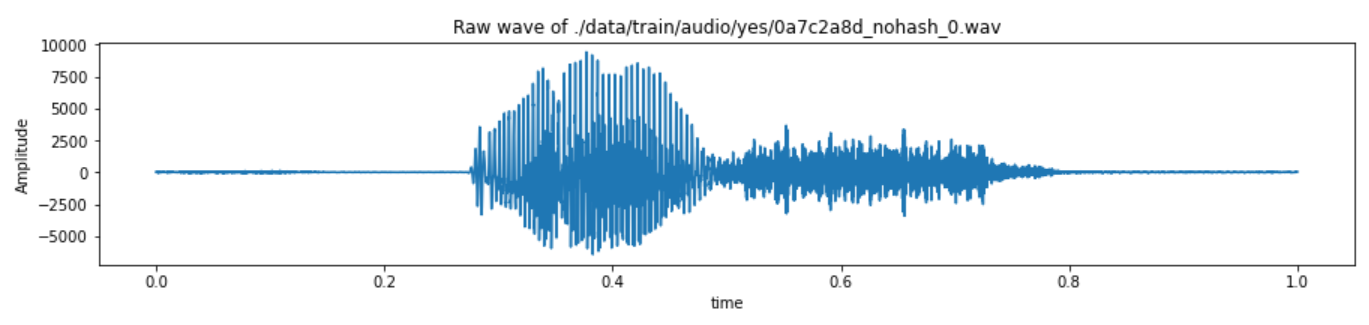
Number of recordings for each command.
labels = os.listdir(train_audio_path)
no_of_recordings=[]
for label in labels:
waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')]
no_of_recordings.append(len(waves))
plt.figure(figsize=(15, 6))
plt.bar(np.arange(len(labels)), no_of_recordings)
plt.xlabel('Commands', fontsize=12)
plt.ylabel('No of recordings', fontsize=12)
plt.xticks(np.arange(len(labels)), labels, fontsize=15, rotation=90)
plt.title('No. of recordings for each command')
plt.show()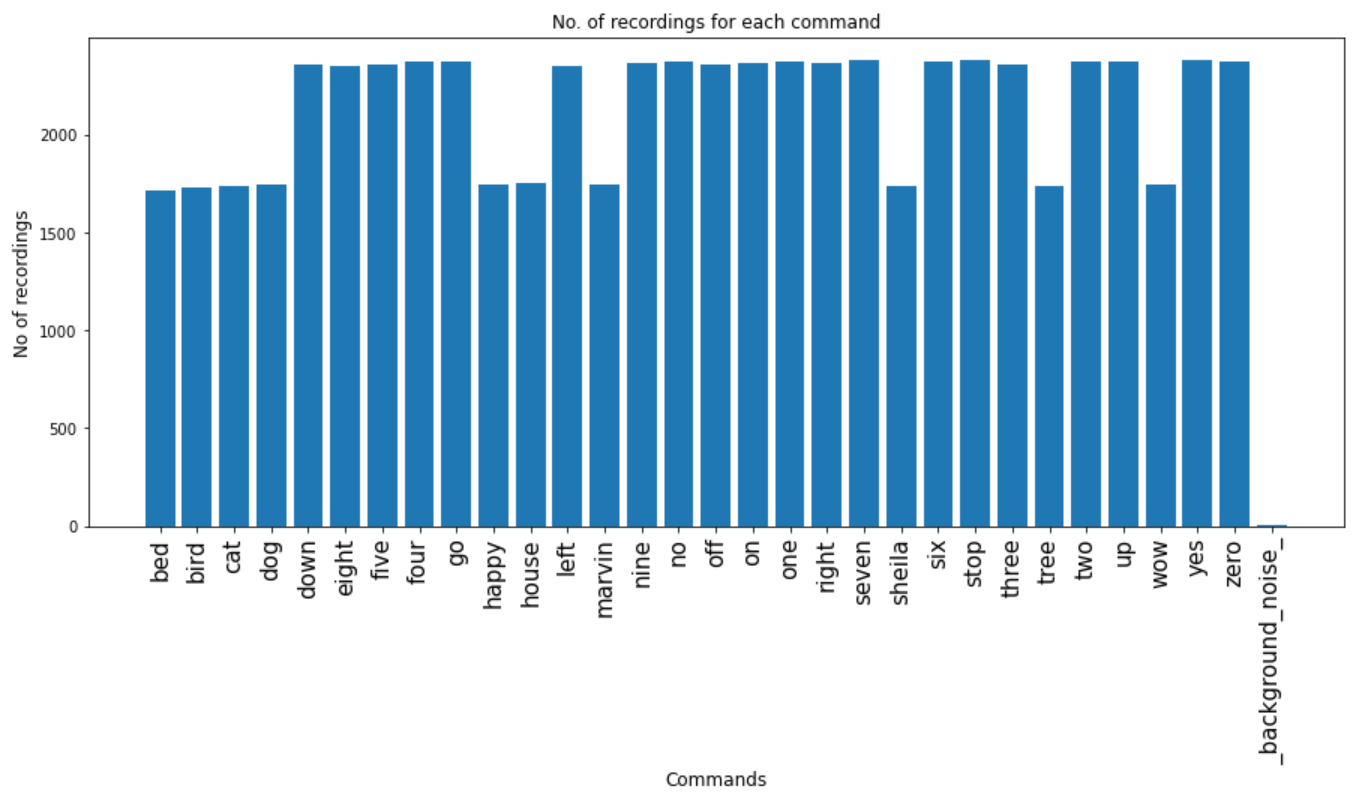
Load all the audio files in every sub-folder.
def load_waves_and_labels(filepath, labels):
all_wave, all_label = [], []
for label in tqdm(labels):
waves = [f for f in os.listdir(filepath + '/'+ label) if f.endswith('.wav')]
for wav in waves:
samples, sample_rate = librosa.load(train_audio_path + '/' + label + '/' + wav, sr=16000)
samples = librosa.resample(samples, sample_rate, 8000)
if (len(samples)==8000):
all_wave.append(samples)
all_label.append(label)
return all_wave, all_label
train_audio_path = './data/train/audio/'
all_wave, all_label = load_waves_and_labels(train_audio_path, labels)
all_wave = np.array(all_wave).reshape(-1, 8000, 1)Feature Extraction
The Mel-Frequency Cepstral Coefficients (MFCC) feature extraction method is a popular method for extracting speech features, and current research aims to improve its performance. MFCC is a method that uses voice samples as input. It calculates coefficients that are unique to each sample after processing. To perform MFCC in this project, a library called python_speech_features is used.
def compute_mfcc(data, n_mfcc, sr=16000):
print('Compute MFCC, n_mfcc=' + str(n_mfcc), flush=True)
all_mfcc = []
for wav in tqdm(data):
feature = mfcc(wav.reshape(-1, ), sr, numcep=n_mfcc)
all_mfcc.append(feature)
return np.array(all_mfcc)
all_mfcc = compute_mfcc(all_wave, n_mfcc=20, sr=8000)As a result, this is a multi-classification problem in which we must encode target labels with values ranging from 0 to n_classes-1.
le = LabelEncoder()
y = le.fit_transform(all_label)
classes = list(le.classes_)Construct Dataset and Dataloader
class SpeechDataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.y)
def __str__(self):
return f"<Dataset(N={len(self)})>"
def __getitem__(self, index):
X = self.X[index, :, :]
y = self.y[index]
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
return [X, y]
def create_dataloader(self, batch_size, shuffle=False, drop_last=False):
return torch.utils.data.DataLoader(
dataset=self,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
pin_memory=True)Segregating your dataset is essential for an unbiased evaluation of prediction performance.
X_train, X_valid, y_train, y_valid = train_test_split(all_mfcc,
y,
test_size=0.3,
random_state=914,
stratify=y)
X_valid, X_test, y_valid, y_test = train_test_split(X_valid,
y_valid,
test_size=0.5,
random_state=914,
stratify=y_valid)Construct dataset and dataloader.
train_dataset = SpeechDataset(X=X_train, y=y_train)
valid_dataset = SpeechDataset(X=X_valid, y=y_valid)
test_dataset = SpeechDataset(X=X_test, y=y_test)
train_dataloader = train_dataset.create_dataloader(batch_size=16)
valid_dataloader = valid_dataset.create_dataloader(batch_size=16)
test_dataloader = test_dataset.create_dataloader(batch_size=16)Build Model
TDNN (Time Delay Neural Network)
TDNNs were first established in 1989 to overcome challenges in speech recognition and were initially focused on shift-invariant phoneme detection. Because spoken sounds are rarely uniform in length and exact segmentation is difficult or impossible, speech lends itself well to TDNNs. The TDNN can develop a model for the key elements of a sound in a time-shift invariant manner by scanning it in the past and future. Because sounds are blurred out by reverberation, this is very useful. Pre-training and joining smaller networks can be used to build large phonetic TDNNs in a modular fashion.
class TDNN(nn.Module):
def __init__(
self,
input_dim=23,
output_dim=512,
context_size=5,
stride=1,
dilation=1,
batch_norm=True,
dropout_p=0.0,
padding=0
):
super(TDNN, self).__init__()
self.context_size = context_size
self.stride = stride
self.input_dim = input_dim
self.output_dim = output_dim
self.dilation = dilation
self.dropout_p = dropout_p
self.padding = padding
self.kernel = nn.Conv1d(self.input_dim,
self.output_dim,
self.context_size,
stride=self.stride,
padding=self.padding,
dilation=self.dilation)
self.nonlinearity = nn.ReLU()
self.batch_norm = batch_norm
if batch_norm:
self.bn = nn.BatchNorm1d(output_dim)
self.drop = nn.Dropout(p=self.dropout_p)
def forward(self, x):
'''
input: size (batch, seq_len, input_features)
outpu: size (batch, new_seq_len, output_features)
'''
_, _, d = x.shape
assert (d == self.input_dim), 'Input dimension was wrong. Expected ({}), got ({})'.format(
self.input_dim, d)
x = self.kernel(x.transpose(1, 2))
x = self.nonlinearity(x)
x = self.drop(x)
if self.batch_norm:
x = self.bn(x)
return x.transpose(1, 2)Statistics Pooling
The statistics pooling layer calculates the mean and standard deviation of the DNN’s frame-level output vectors. The DNN uses this pooling approach to create fixed-length representations from variable-length speech segments.
class StatsPool(nn.Module):
def __init__(self, floor=1e-10, bessel=False):
super(StatsPool, self).__init__()
self.floor = floor
self.bessel = bessel
def forward(self, x):
means = torch.mean(x, dim=1)
_, t, _ = x.shape
if self.bessel:
t = t - 1
residuals = x - means.unsqueeze(1)
numerator = torch.sum(residuals**2, dim=1)
stds = torch.sqrt(torch.clamp(numerator, min=self.floor)/t)
x = torch.cat([means, stds], dim=1)
return xX-Vectors
Variable-length utterances are mapped to fixed-dimensional embeddings called x-vectors by the DNN, which has been trained to discriminate between speakers (Snyder et al., 2018).
Usual trick here is that if your stride is 1 an dilation is 1 and your kernel has an odd size, you can set the padding to be
floor(kernel_size/2). By doing so, you can ensure Conv1d retains the same shape.
class XVectors(nn.Module):
def __init__(
self,
dropout_p=0.0,
n_classes=30
):
super(XVectors, self).__init__()
self.tdnn1 = TDNN(input_dim=20, context_size=3, padding=math.floor(3/2))
self.tdnn2 = TDNN(input_dim=512, context_size=1, padding=math.floor(1/2))
self.tdnn3 = TDNN(input_dim=512, output_dim=1500, context_size=1, padding=math.floor(1/2))
self.tdnnres1 = TDNN(input_dim=512, context_size=5, padding=math.floor(5/2))
self.tdnnres2 = TDNN(input_dim=512, context_size=5, padding=math.floor(5/2))
self.tdnnres3 = TDNN(input_dim=512, context_size=1, padding=math.floor(1/2))
self.pool = StatsPool()
self.linear1 = nn.Linear(3000, 512)
self.linear2 = nn.Linear(512, 512)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(512)
self.dropout1 = nn.Dropout(p=dropout_p)
self.dropout2 = nn.Dropout(p=dropout_p)
self.nonlinearity = nn.ReLU()
self.classifier = nn.Linear(512, n_classes)
def forward(self, x):
# Residual TDNN based Frame-level Feature Extractor
x = self.tdnn1(x)
x = self.tdnn2(x)
x = self.tdnnres1(x) + x
x = self.tdnnres2(x) + x
x = self.tdnnres3(x) + x
x = self.tdnn3(x)
# Statistics Pooling
x = self.pool(x)
# DNN based Segment level Feature Extractor
x = self.linear1(x)
x = self.nonlinearity(self.dropout1(self.bn1(x)))
x = self.linear2(x)
x = self.nonlinearity(self.dropout2(self.bn2(x)))
# Classifier
x = self.classifier(x)
return xBuild Trainer
Once you’ve organised the PyTorch code, the Trainer automates everything else. It’s the same thing PyTorch Lightning is up to.
class Trainer(object):
def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):
# Set params
self.model = model
self.device = device
self.loss_fn = loss_fn
self.optimizer = optimizer
self.scheduler = scheduler
def train_step(self, dataloader):
"""Train step."""
# Set model to train mode
self.model.train()
loss = 0.0
# Iterate over train batches
for i, batch in enumerate(dataloader):
# Step
batch = [item.to(self.device) for item in batch]
inputs, targets = batch[:-1], batch[-1]
self.optimizer.zero_grad()
z = self.model(inputs[0])
J = self.loss_fn(z, targets)
J.backward()
nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
self.optimizer.step()
# Cumulative Metrics
loss += (J.detach().item() - loss) / (i + 1)
return loss
def eval_step(self, dataloader):
"""Validation or test step."""
# Set model to eval mode
self.model.eval()
loss = 0.0
y_trues, y_probs = [], []
# Iterate over val batches
with torch.no_grad():
for i, batch in enumerate(dataloader):
# Step
batch = [item.to(self.device) for item in batch]
inputs, y_true = batch[:-1], batch[-1]
z = self.model(inputs[0])
J = self.loss_fn(z, y_true).item()
# Cumulative Metrics
loss += (J - loss) / (i + 1)
# Store outputs
y_prob = torch.sigmoid(z).cpu().numpy()
y_probs.extend(y_prob)
y_trues.extend(y_true.cpu().numpy())
return loss, np.vstack(y_trues), np.vstack(y_probs)
def predict_step(self, dataloader):
"""Prediction step."""
# Set model to eval mode
self.model.eval()
y_probs = []
# Iterate over val batches
with torch.no_grad():
for i, batch in enumerate(dataloader):
batch = [item.to(self.device) for item in batch]
# Forward pass with inputs
inputs, targets = batch[:-1], batch[-1]
y_prob = self.model(inputs[0])
# Store outputs
y_probs.extend(y_prob.cpu())
return self.softmax(np.vstack(y_probs))
def softmax(self, x):
"""Compute softmax values for each sets of scores in x."""
exp_ = np.exp(x - np.max(x))
return exp_ / exp_.sum(axis=0)
def train(self, num_epochs, patience, train_dataloader, val_dataloader):
best_val_loss = np.inf
self.train_losses, self.valid_losses = [], []
for epoch in range(num_epochs):
# Steps
train_loss = self.train_step(dataloader=train_dataloader)
valid_loss, y_trues, y_probs = self.eval_step(dataloader=val_dataloader)
self.train_losses.append(train_loss)
self.valid_losses.append(valid_loss)
y_preds = np.argmax(y_probs, axis=1)
val_f1 = f1_score(y_trues, y_preds, average="weighted")
self.scheduler.step(valid_loss)
# Early stopping
if valid_loss < best_val_loss:
best_val_loss = valid_loss
best_model = self.model
_patience = patience
else:
_patience -= 1
if not _patience:
print("Stopping early!")
break
# Logging
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.5f}, "
f"val_loss: {valid_loss:.5f}, "
f"val_f1: {val_f1:.5f}, "
f"lr: {self.optimizer.param_groups[0]['lr']:.2E}, "
f"_patience: {_patience}"
)
return best_modelLet’s see what our model looks like.
model = XVectors(dropout_p=0.1, n_classes=len(classes))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
print(model.named_parameters)<bound method Module.named_parameters of XVectors(
(tdnn1): TDNN(
(kernel): Conv1d(20, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(nonlinearity): ReLU()
(bn): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop): Dropout(p=0.0, inplace=False)
)
(tdnn2): TDNN(
(kernel): Conv1d(512, 512, kernel_size=(1,), stride=(1,))
(nonlinearity): ReLU()
(bn): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop): Dropout(p=0.0, inplace=False)
)
(tdnn3): TDNN(
(kernel): Conv1d(512, 1500, kernel_size=(1,), stride=(1,))
(nonlinearity): ReLU()
(bn): BatchNorm1d(1500, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop): Dropout(p=0.0, inplace=False)
)
(tdnnres1): TDNN(
(kernel): Conv1d(512, 512, kernel_size=(5,), stride=(1,), padding=(2,))
(nonlinearity): ReLU()
(bn): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop): Dropout(p=0.0, inplace=False)
)
(tdnnres2): TDNN(
(kernel): Conv1d(512, 512, kernel_size=(5,), stride=(1,), padding=(2,))
(nonlinearity): ReLU()
(bn): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop): Dropout(p=0.0, inplace=False)
)
(tdnnres3): TDNN(
(kernel): Conv1d(512, 512, kernel_size=(1,), stride=(1,))
(nonlinearity): ReLU()
(bn): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(drop): Dropout(p=0.0, inplace=False)
)
(pool): StatsPool()
(linear1): Linear(in_features=3000, out_features=512, bias=True)
(linear2): Linear(in_features=512, out_features=512, bias=True)
(bn1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(nonlinearity): ReLU()
(classifier): Linear(in_features=512, out_features=30, bias=True)
)>Start Training
Set up loss function, optimiser, and scheduler.
lr = 2e-4
num_epochs = 40
patience = 10
loss_fn = nn.CrossEntropyLoss()
optimiser = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimiser, mode='min', factor=0.1, patience=5)Set up Trainer.
trainer = Trainer(
model=model,
device=device,
loss_fn=loss_fn,
optimizer=optimiser,
scheduler=scheduler
)Start training!
best_model = trainer.train(num_epochs, patience, train_dataloader, valid_dataloader)Performance
plt.figure(figsize=(15, 6))
plt.plot(range(1, len(trainer.train_losses)+1), trainer.train_losses, label="train")
plt.plot(range(1, len(trainer.valid_losses)+1), trainer.valid_losses, label="valid")
plt.legend()
plt.grid()
plt.show()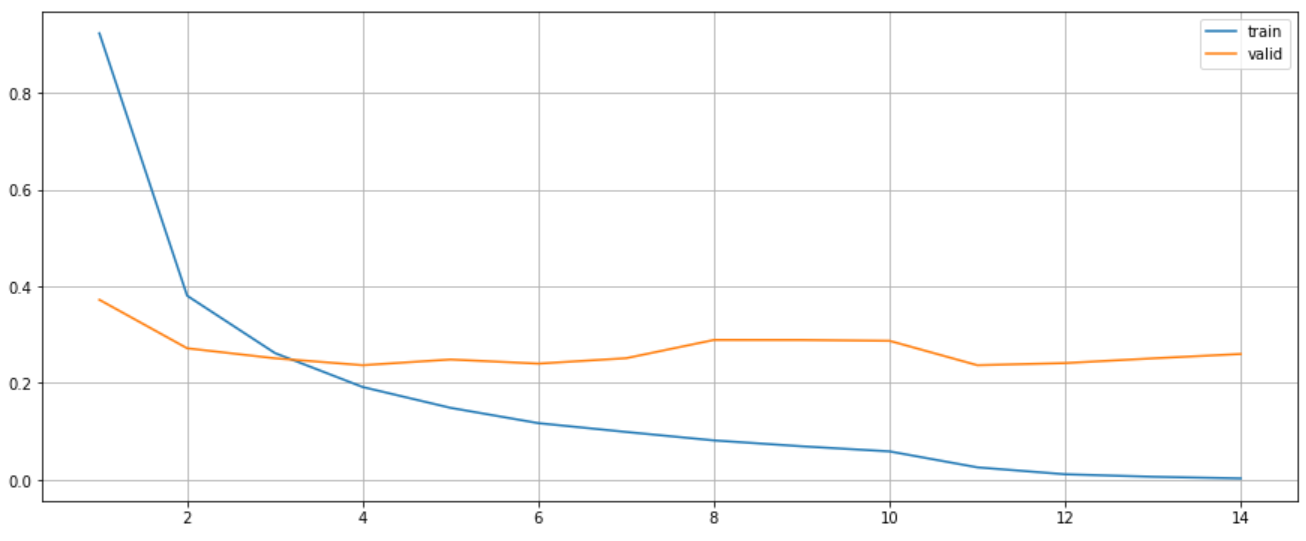
The f1 score in test set is 0.9435.
test_probs = trainer.predict_step(test_dataloader)
test_preds = np.argmax(test_probs, axis=1)
f1_score(y_test, test_preds, average='weighted')
