Introduction
There are two major applications of speaker recognition technologies and methodologies. The job of detecting which speaker made a given speech is similar to that of multiclass classification when performed for a closed group of speakers. On the other hand, speaker verification includes assessing whether a particular speech and a target model match.
Dataset
In this article, TIMIT dataset is used. The TIMIT speech corpus is intended to offer speech data for acoustic-phonetic studies as well as the creation and testing of automatic speech recognition systems. TIMIT features broadband recordings of 630 speakers reading ten phonetically rich sentences in eight major dialects of American English.
| Name | Conditions | Free | POI | Utterances |
|---|---|---|---|---|
| ELSDSR | Clean Speech | YES | 22 | 198 |
| MIT Mobile | Mobile Devices | - | 88 | 7884 |
| SWB | Telephony | - | 3114 | 33039 |
| POLYCOST | Telephony | - | 133 | 1285 |
| ICSI Meeting Corpus | Meetings | - | 53 | 922 |
| Fprensic Comparison | Telephony | YES | 552 | 1264 |
| ANDOSL | Clean Speech | - | 204 | 33900 |
| TIMIT | Clean Speech | - | 630 | 6300 |
| SITW | Multi-media | YES | 299 | 2800 |
| NIST SRE | Clean Speech | - | 2000+ | * |
| VoxCeleb | Multi-media | YES | 1251 | 153516 |
The output of the last layer is input into a 630-way softmax to obtain a distribution over the 630 different speakers, as identification is handled as a simple classification task.
Import Libraries
In this work, Librosa is used for audio analysis and PyTorch is used to construct the models.
import math
import random
import librosa
import librosa.display
import python_speech_features
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pytorch_lightning as pl
import torch.nn.functional as F
from scipy.special import softmax
from scipy.io import wavfile
from tqdm.auto import tqdm
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from collections import OrderedDict
from datasets import load_dataset
torch.manual_seed(914)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = FalseLoad Data
Datasets is a lightweight library providing one-line dataloaders for many public datasets built by HuggingFace. There are 3780 utterances in the training set, 1260 utterances in the validation set, and 1260 utterances in the test set.
timit = load_dataset('timit_asr')
timit_train_df = timit["train"].to_pandas()
timit_test_df = timit["test"].to_pandas()
timit_df = pd.concat([timit_train_df, timit_test_df], axis=0).reset_index(drop=True)
timit_train_df, timit_test_df = train_test_split(
timit_df,
test_size=0.2,
random_state=914,
stratify=timit_df.speaker_id
)
timit_train_df = timit_train_df.reset_index(drop=True)
timit_test_df = timit_test_df.reset_index(drop=True)
timit_train_df = timit_train_df.sort_values("speaker_id").reset_index(drop=True)
timit_test_df = timit_test_df.sort_values("speaker_id").reset_index(drop=True)Helper Functions
The data are unequal in length, so the training data are randomly intercepted due to the fixed input size of neural network. If the training data is only taken for the first 1 second, there is too much data loss and the result is definitely poor. Theoretically, the training data should be intercepted more often, without data loss.
Let’s say we train the dataset and have 1000 unequal lengths of data. Each time we randomly intercept, pick a random piece of data and intercept a random 1 second in this data. Repeat this operation many times, say 100 times, so that we get 100 1-second data to train. generate_segments() function is to produce num_samples fixed-size contiguous subarrays. Some of the array length is less than 16000, so padding() function is used to pad the sequence to a longer length in order to generate subarray.
def generate_segments(sample, windows, num_samples):
lst = range(len(sample))
list_size = len(lst)
indexes = [lst[i:i+windows] for i in range(list_size-windows+1)]
indexes = random.choices(indexes, k=num_samples)
sub_lst = [sample[min(idx):max(idx)] for idx in indexes]
return sub_lst
def padding(arr, max_length):
padding = np.zeros(max_length)
padding[:len(arr)] = arr
return paddingCreating Training Data
In TIMIT data, most of the audio file is about 3 seconds, and we will only use one second data as our input. If the sampling rate is 16kHz, then we have 48000 sample points in the sequence. First step is to randomly select several 16000 contiguous subsequences from the original, this can be done using generate_segments() function. If the original sequence is shorter than length of 16000, then padding() function is used to pad the sequence to a larger length.
sample_rate = 16000
segments = 100
all_wave, all_label = [], []
for idx in tqdm(range(len(timit_train_df))):
samples, sample_rate = librosa.load(timit_train_df.file[idx], sr=sample_rate)
if len(samples) < sample_rate:
samples = padding(samples, int(sample_rate*1.5))
samples_segments = generate_segments(samples, windows=sample_rate, num_samples=segments)
label = timit_train_df.speaker_id[idx]
all_wave.extend(samples_segments)
all_label.extend([label]*segments)
all_wave = np.array(all_wave)
all_label = np.array(all_label)
le = LabelEncoder()
y = le.fit_transform(all_label)
classes = list(le.classes_)Compute MFCC
The 20 dimensional MFCC features are used.
def compute_mfcc(data, n_mfcc, sr=16000):
print('Compute MFCC, n_mfcc=' + str(n_mfcc), flush=True)
all_mfcc = []
for wav in tqdm(data):
feature = python_speech_features.mfcc(wav,
samplerate=sr,
numcep=n_mfcc,
nfft=int(sr*0.025))
all_mfcc.append(feature)
return np.array(all_mfcc)
all_mfcc = compute_mfcc(all_wave, 20)Creating Test Data
When testing, we divide a data sample into many 1-second data, for example, we use sliding window to divide a certain data sample into 10 1-second data, the final test will get 10 softmax results. Average these 10 softmax results into one vector and get the result.
sample_rate = 16000
segments = 10
all_wave_test, all_label_test = [], []
for idx in tqdm(range(len(timit_test_df))):
samples, sample_rate = librosa.load(timit_test_df.file[idx], sr=sample_rate)
if len(samples) < sample_rate:
samples = padding(samples, int(sample_rate*1.5))
samples_segments = generate_segments(samples, windows=sample_rate, num_samples=segments)
label = timit_test_df.speaker_id[idx]
all_wave_test.extend(samples_segments)
all_label_test.extend([label]*segments)
all_wave_test = np.array(all_wave_test)
all_label_test = np.array(all_label_test)
all_mfcc_test = compute_mfcc(all_wave_test, 20)
X_test = all_mfcc_test
y_test = le.transform(all_label_test) Split Data into Training and Validation
X_train, X_valid, y_train, y_valid = train_test_split(
all_mfcc,
y,
test_size=0.25,
random_state=914,
stratify=y
)Normalisation
mean_ = np.mean(X_train, axis=0)
std_ = np.std(X_train, axis=0)
X_train = (X_train - mean_) / std_
X_valid = (X_valid - mean_) / std_
X_test = (X_test - mean_) / std_Construct Dataset and Dataloader
class SpeechDataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.y)
def __str__(self):
return f"<Dataset(N={len(self)})>"
def __getitem__(self, index):
X = self.X[index, :, :]
y = self.y[index]
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
return [X, y]
def create_dataloader(self, batch_size, shuffle=False, drop_last=False):
return torch.utils.data.DataLoader(
dataset=self,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
pin_memory=True)batch_size = 128
train_dataset = SpeechDataset(X=X_train, y=y_train)
valid_dataset = SpeechDataset(X=X_valid, y=y_valid)
test_dataset = SpeechDataset(X=X_test, y=y_test)
train_dataloader = train_dataset.create_dataloader(batch_size=batch_size, shuffle=True)
valid_dataloader = valid_dataset.create_dataloader(batch_size=batch_size, shuffle=False)
test_dataloader = test_dataset.create_dataloader(batch_size=batch_size, shuffle=False)
batch_X, batch_y = next(iter(train_dataloader))
print ("Sample batch:\n"
f" X: {list(batch_X.size())}\n"
f" y: {list(batch_y.size())}")Modelling
Building LightningModule
LightningModule is a subclass of torch.nn.Module, and it is used for both inference and training.
class LightningMultiClass(pl.LightningModule):
"""
Multi-class Classification Engine
"""
learning_rate = 1e-3
def __init__(self):
super().__init__()
self.train_losses = []
self.valid_losses = []
self.train_accuracies = []
self.valid_accuracies = []
def forward(self, inputs):
raise NotImplementedError
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
def training_step(self, batch, batch_idx):
batch, y = batch
y_hat = self(batch)
labels_hat = torch.argmax(y_hat, dim=1)
n_correct_pred = torch.sum(y == labels_hat).item()
loss = F.cross_entropy(y_hat, y.long())
self.log("train_loss", loss, on_step=True, on_epoch=True, logger=False)
return {'loss': loss, "n_correct_pred": n_correct_pred, "n_pred": len(y)}
def training_epoch_end(self, outputs):
avg_loss = torch.stack([x['loss'] for x in outputs]).mean()
train_acc = sum([x['n_correct_pred'] for x in outputs]) / sum(x['n_pred'] for x in outputs)
self.train_losses.append(avg_loss.detach().cpu().item())
self.train_accuracies.append(train_acc)
def validation_step(self, batch, batch_idx):
batch, y = batch
y_hat = self(batch)
loss = F.cross_entropy(y_hat, y.long())
labels_hat = torch.argmax(y_hat, dim=1)
n_correct_pred = torch.sum(y == labels_hat).item()
self.log("valid_loss", loss, on_step=True, on_epoch=True, logger=False)
return {'val_loss': loss, "n_correct_pred": n_correct_pred, "n_pred": len(y)}
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
val_acc = sum([x['n_correct_pred'] for x in outputs]) / sum(x['n_pred'] for x in outputs)
self.valid_losses.append(avg_loss.detach().cpu().item())
self.valid_accuracies.append(val_acc)
def test_step(self, batch, batch_idx):
batch, y = batch
y_hat = self(batch)
loss = F.cross_entropy(y_hat, y.long())
labels_hat = torch.argmax(y_hat, dim=1)
n_correct_pred = torch.sum(y == labels_hat).item()
return {'test_loss': loss, "n_correct_pred": n_correct_pred, "n_pred": len(y)}
def test_epoch_end(self, outputs):
avg_loss = torch.stack([x['test_loss'] for x in outputs]).mean()
test_acc = sum([x['n_correct_pred'] for x in outputs]) / sum(x['n_pred'] for x in outputs)
def predict_proba(self, test_dataloader):
# Set model to eval mode
self.eval()
y_probs = []
# Iterate over val batches
with torch.no_grad():
for i, batch in enumerate(tqdm(test_dataloader)):
x, y = batch
x, y = x.to(self.device), y.to(self.device)
# Forward pass with inputs
y_prob = self(x)
# Store outputs
y_probs.extend(y_prob.cpu())
return softmax(np.vstack(y_probs), axis=1)Baseline
In recent years, increased emphasis has been placed on using neural networks for speaker verification, with end-to-end training being used by the most successful systems. The neural network output vectors are commonly referred to as embedding vectors, also known as d-vectors, in such systems.
In this work, LSTM-based d-vector and LSTM-based d-vector with Attentive Pooling are used for constructing baseline (Li et al., 2020).
class LSTMDvector(LightningMultiClass):
"""
LSTM-based d-vector
"""
def __init__(
self,
num_layers=3,
dim_input=40,
dim_cell=256,
dim_emb=256,
seg_len=160,
dropout_p=0.1,
num_classes=30
):
super().__init__()
self.lstm = nn.LSTM(dim_input, dim_cell, num_layers, batch_first=True)
self.embedding = nn.Linear(dim_cell, dim_emb)
self.seg_len = seg_len
self.classifier = nn.Linear(dim_emb, num_classes)
def forward(self, inputs):
lstm_outs, _ = self.lstm(inputs)
embeds = self.embedding(lstm_outs[:, -1, :])
x = embeds.div(embeds.norm(p=2, dim=-1, keepdim=True))
return self.classifier(x)
class AttentivePooledLSTMDvector(LightningMultiClass):
"""
LSTM-based d-vector with Attentive Pooling
"""
def __init__(
self,
num_layers=3,
dim_input=40,
dim_cell=256,
dim_emb=256,
seg_len=160,
num_classes=30
):
super().__init__()
self.lstm = nn.LSTM(dim_input, dim_cell, num_layers, batch_first=True)
self.embedding = nn.Linear(dim_cell, dim_emb)
self.linear = nn.Linear(dim_emb, 1)
self.seg_len = seg_len
self.classifier = nn.Linear(dim_emb, num_classes)
def forward(self, inputs):
lstm_outs, _ = self.lstm(inputs)
embeds = torch.tanh(self.embedding(lstm_outs))
attn_weights = F.softmax(self.linear(embeds), dim=1)
embeds = torch.sum(embeds * attn_weights, dim=1)
embeds = embeds.div(embeds.norm(p=2, dim=-1, keepdim=True))
return self.classifier(embeds)XVectors
x-vector system is based on the DNN embeddings in Snyder et al. paper “Deep neural network embeddings for text-independent speaker verification” in 2017. The features are 20 dimensional mfcc with a frame-length of 25ms, mean-normalized over a sliding window of up to 1 seconds.
There are three parts within the architecture of Speaker Embedding Model: frame-level feature extractor, statistics pooling and segment-level feature extractor. In frame-level feature extractor, the network consists of TDNN layers and residual TDNN blocks (Hossein et al., 2019). Statistics pooling operation is then used, the output is feed into the segment-level feature extractor. There are two fully-connected layers in segment-level feature extractor.
class XVectors(LightningMultiClass):
def __init__(
self,
dropout_p=0.0,
n_classes=30
):
super(XVectors, self).__init__()
self.tdnn1 = TDNN(input_dim=20, context_size=5, padding=math.floor(5/2))
self.tdnn2 = TDNN(input_dim=512, context_size=5, padding=math.floor(5/2))
self.tdnn3 = TDNN(input_dim=512, output_dim=1500, context_size=1, padding=math.floor(1/2))
self.tdnnres1 = TDNN(input_dim=512, context_size=7, padding=math.floor(7/2))
self.tdnnres2 = TDNN(input_dim=512, context_size=1, padding=math.floor(1/2))
self.tdnnres3 = TDNN(input_dim=512, context_size=1, padding=math.floor(1/2))
self.pool = StatsPool()
self.linear1 = nn.Linear(3000, 512)
self.linear2 = nn.Linear(512, 512)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(512)
self.dropout1 = nn.Dropout(p=dropout_p)
self.dropout2 = nn.Dropout(p=dropout_p)
self.nonlinearity = nn.ReLU()
self.classifier = nn.Linear(512, n_classes)
def forward(self, x):
# Residual TDNN based Frame-level Feature Extractor
x = self.tdnn1(x)
x = self.tdnn2(x)
x = self.tdnnres1(x) + x
x = self.tdnnres2(x) + x
x = self.tdnnres3(x) + x
x = self.tdnn3(x)
# Statistics Pooling
x = self.pool(x)
# DNN based Segment level Feature Extractor
x = self.linear1(x)
x = self.nonlinearity(self.dropout1(self.bn1(x)))
x = self.linear2(x)
x = self.nonlinearity(self.dropout2(self.bn2(x)))
# Classifier
x = self.classifier(x)
return x
class StatsPool(nn.Module):
def __init__(self, floor=1e-10, bessel=False):
super(StatsPool, self).__init__()
self.floor = floor
self.bessel = bessel
def forward(self, x):
means = torch.mean(x, dim=1)
_, t, _ = x.shape
if self.bessel:
t = t - 1
residuals = x - means.unsqueeze(1)
numerator = torch.sum(residuals**2, dim=1)
stds = torch.sqrt(torch.clamp(numerator, min=self.floor)/t)
x = torch.cat([means, stds], dim=1)
return x
class TDNN(nn.Module):
def __init__(
self,
input_dim=23,
output_dim=512,
context_size=5,
stride=1,
dilation=1,
batch_norm=True,
dropout_p=0.0,
padding=0
):
super(TDNN, self).__init__()
self.context_size = context_size
self.stride = stride
self.input_dim = input_dim
self.output_dim = output_dim
self.dilation = dilation
self.dropout_p = dropout_p
self.padding = padding
self.kernel = nn.Conv1d(self.input_dim,
self.output_dim,
self.context_size,
stride=self.stride,
padding=self.padding,
dilation=self.dilation)
self.nonlinearity = nn.ReLU()
self.batch_norm = batch_norm
if batch_norm:
self.bn = nn.BatchNorm1d(output_dim)
self.drop = nn.Dropout(p=self.dropout_p)
def forward(self, x):
'''
input: size (batch, seq_len, input_features)
outpu: size (batch, new_seq_len, output_features)
'''
_, _, d = x.shape
x = self.kernel(x.transpose(1, 2))
x = self.nonlinearity(x)
x = self.drop(x)
if self.batch_norm:
x = self.bn(x)
return x.transpose(1, 2)Start Training
xvectors = XVectors(n_classes=len(classes))
trainer = pl.Trainer(gpus=1,
deterministic=True,
max_epochs=20,
precision=16,
num_sanity_val_steps=0,
fast_dev_run=False)
trainer.fit(xvectors, train_dataloader, valid_dataloader)Evaluate Test Set
- Use sliding window to divide a certain data sample into 10 1-second data, the final test will get 10 softmax results.
- Average these 10 softmax results into one vector and get the argmax result.
y_test_proba = xvectors.predict_proba(test_dataloader)
y_test_proba_final = []
for i in range(y_test_proba.shape[0]//10):
batch = y_test_proba[10*i:10*i+10, :]
batch_mean = np.mean(batch, axis=0)
y_test_proba_final.append(batch_mean)
y_test_proba_final = np.array(y_test_proba_final)
y_test_pred = np.argmax(y_test_proba_final, axis=1)
y_test_ground_truth = le.transform(timit_test_df.speaker_id)
metrics.top_k_accuracy_score(y_test_ground_truth, y_test_proba_final, k=1)Loss curve
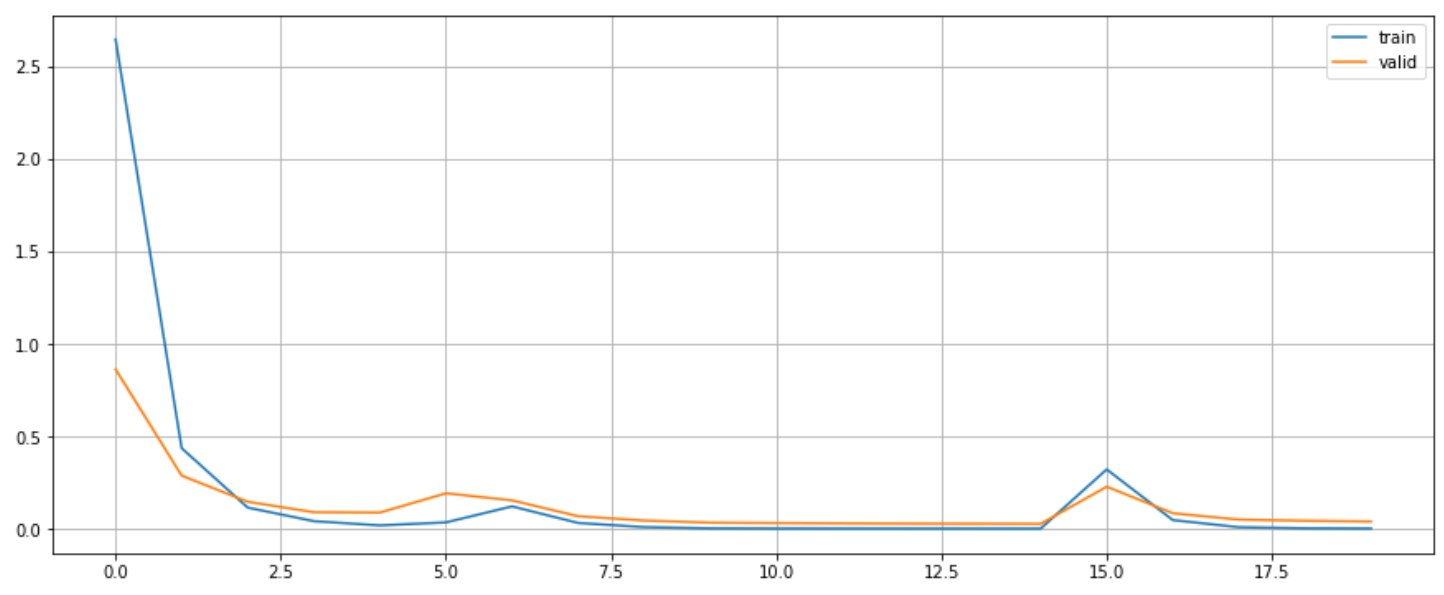
Accuracy curve
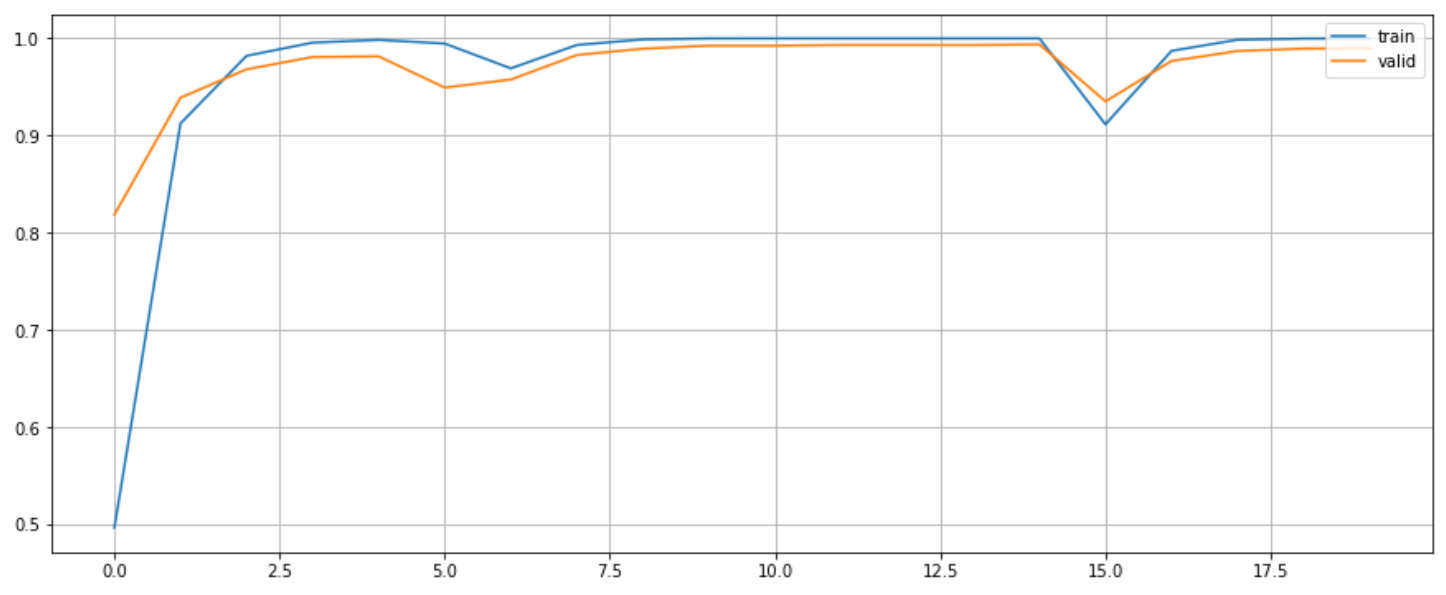
Performance
10-Segment
| Model | Size | Accuracy |
|---|---|---|
| LSTM-DVectors | (37800, 12600, 1260) | 63.3334% |
| Attn-LSTM-DVectors | (37800, 12600, 1260) | 79.5238% |
| XVectors | (37800, 12600, 1260) | 98.4127% |
20-Segment
| Model | Size | Accuracy |
|---|---|---|
| LSTM-DVectors | (75600, 25200, 1260) | 76.2698% |
| Attn-LSTM-DVectors | (75600, 25200, 1260) | 83.0159% |
| XVectors | (75600, 25200, 1260) | 96.0317% |
100-Segment
| Model | Size | Accuracy |
|---|---|---|
| LSTM-DVectors | (378000, 126000, 1260) | 86.2698% |
| Attn-LSTM-DVectors | (378000, 126000, 1260) | 92.1428% |
| XVectors | (378000, 126000, 1260) | 97.6984% |

